Ancestral reconstruction (also known as Character Mapping or Character Optimization) is the extrapolation back in time from measured characteristics of individuals, populations, or species to their common ancestors. It is an important application of phylogenetics, the reconstruction and study of the evolutionary relationships among individuals, populations or species to their ancestors. In the context of evolutionary biology, ancestral reconstruction can be used to recover different kinds of ancestral character states of organisms that lived millions of years ago.[1] These states include the genetic sequence (ancestral sequence reconstruction), the amino acid sequence of a protein, the composition of a genome (e.g., gene order), a measurable characteristic of an organism (phenotype), and the geographic range of an ancestral population or species (ancestral range reconstruction). This is desirable because it allows us to examine parts of phylogenetic trees corresponding to the distant past, clarifying the evolutionary history of the species in the tree. Since modern genetic sequences are essentially a variation of ancient ones, access to ancient sequences may identify other variations and organisms which could have arisen from those sequences.[2] In addition to genetic sequences, one might attempt to track the changing of one character trait to another, such as fins turning to legs.
Non-biological applications include the reconstruction of the vocabulary or phonemes of ancient languages,[3] and cultural characteristics of ancient societies such as oral traditions[4] or marriage practices.[5]
Ancestral reconstruction relies on a sufficiently realistic statistical model of evolution to accurately recover ancestral states. These models use the genetic information already obtained through methods such as phylogenetics to determine the route that evolution has taken and when evolutionary events occurred.[6] No matter how well the model approximates the actual evolutionary history, however, one's ability to accurately reconstruct an ancestor deteriorates with increasing evolutionary time between that ancestor and its observed descendants. Additionally, more realistic models of evolution are inevitably more complex and difficult to calculate. Progress in the field of ancestral reconstruction has relied heavily on the exponential growth of computing power and the concomitant development of efficient computational algorithms (e.g., a dynamic programming algorithm for the joint maximum likelihood reconstruction of ancestral sequences).[7] Methods of ancestral reconstruction are often applied to a given phylogenetic tree that has already been inferred from the same data. While convenient, this approach has the disadvantage that its results are contingent on the accuracy of a single phylogenetic tree. In contrast, some researchers[8] advocate a more computationally intensive Bayesian approach that accounts for uncertainty in tree reconstruction by evaluating ancestral reconstructions over many trees.
History
editThe concept of ancestral reconstruction is often credited to Emile Zuckerkandl and Linus Pauling. Motivated by the development of techniques for determining the primary (amino acid) sequence of proteins by Frederick Sanger in 1955,[9] Zuckerkandl and Pauling postulated[10] that such sequences could be used to infer not only the phylogeny relating the observed protein sequences, but also the ancestral protein sequence at the earliest point (root) of this tree. However, the idea of reconstructing ancestors from measurable biological characteristics had already been developing in the field of cladistics, one of the precursors of modern phylogenetics. Cladistic methods, which appeared as early as 1901, infer the evolutionary relationships of species on the basis of the distribution of shared characteristics, of which some are inferred to be descended from common ancestors. Furthermore, Theodosius Dobzhansky and Alfred Sturtevant articulated the principles of ancestral reconstruction in a phylogenetic context in 1938, when inferring the evolutionary history of chromosomal inversions in Drosophila pseudoobscura.[11]
Thus, ancestral reconstruction has its roots in several disciplines. Today, computational methods for ancestral reconstruction continue to be extended and applied in a diversity of settings, so that ancestral states are being inferred not only for biological characteristics and the molecular sequences, but also for the structure[12][13] or catalytic properties[14] of ancient versus modern proteins, the geographic location of populations and species (phylogeography)[15][16] and the higher-order structure of genomes.[17]
Methods and algorithms
editAny attempt at ancestral reconstruction begins with a phylogeny. In general, a phylogeny is a tree-based hypothesis about the order in which populations (referred to as taxa) are related by descent from common ancestors. Observed taxa are represented by the tips or terminal nodes of the tree that are progressively connected by branches to their common ancestors, which are represented by the branching points of the tree that are usually referred to as the ancestral or internal nodes. Eventually, all lineages converge to the most recent common ancestor of the entire sample of taxa. In the context of ancestral reconstruction, a phylogeny is often treated as though it were a known quantity (with Bayesian approaches being an important exception). Because there can be an enormous number of phylogenies that are nearly equally effective at explaining the data, reducing the subset of phylogenies supported by the data to a single representative, or point estimate, can be a convenient and sometimes necessary simplifying assumption.
Ancestral reconstruction can be thought of as the direct result of applying a hypothetical model of evolution to a given phylogeny. When the model contains one or more free parameters, the overall objective is to estimate these parameters on the basis of measured characteristics among the observed taxa (sequences) that descended from common ancestors. Parsimony is an important exception to this paradigm: though it has been shown that there are circumstances under which it is the maximum likelihood estimator,[18] at its core, it is simply based on the heuristic that changes in character state are rare, without attempting to quantify that rarity.
There are three different classes of method for ancestral reconstruction. In chronological order of discovery, these are maximum parsimony, maximum likelihood, and Bayesian Inference. Maximum parsimony considers all evolutionary events equally likely; maximum likelihood accounts for the differing likelihood of certain classes of event; and Bayesian inference relates the conditional probability of an event to the likelihood of the tree, as well as the amount of uncertainty that is associated with that tree. Maximum parsimony and maximum likelihood yield a single most probable outcome, whereas Bayesian inference accounts for uncertainties in the data and yields a sample of possible trees.
Maximum parsimony
editParsimony, known colloquially as "Occam's razor", refers to the principle of selecting the simplest of competing hypotheses. In the context of ancestral reconstruction, parsimony endeavours to find the distribution of ancestral states within a given tree which minimizes the total number of character state changes that would be necessary to explain the states observed at the tips of the tree. This method of maximum parsimony[19] is one of the earliest formalized algorithms for reconstructing ancestral states, as well as one of the simplest.[13]
Maximum parsimony can be implemented by one of several algorithms. One of the earliest examples is Fitch's method,[20] which assigns ancestral character states by parsimony via two traversals of a rooted binary tree. The first stage is a post-order traversal that proceeds from the tips toward the root of a tree by visiting descendant (child) nodes before their parents. Initially, we are determining the set of possible character states Si for the i-th ancestor based on the observed character states of its descendants. Each assignment is the set intersection of the character states of the ancestor's descendants; if the intersection is the empty set, then it is the set union. In the latter case, it is implied that a character state change has occurred between the ancestor and one of its two immediate descendants. Each such event counts towards the algorithm's cost function, which may be used to discriminate among alternative trees on the basis of maximum parsimony. Next, a pre-order traversal of the tree is performed, proceeding from the root towards the tips. Character states are then assigned to each descendant based on which character states it shares with its parent. Since the root has no parent node, one may be required to select a character state arbitrarily, specifically when more than one possible state has been reconstructed at the root.

For example, consider a phylogeny recovered for a genus of plants containing 6 species A - F, where each plant is pollinated by either a "bee", "hummingbird" or "wind". One obvious question is what the pollinators at deeper nodes were in the phylogeny of this genus of plants. Under maximum parsimony, an ancestral state reconstruction for this clade reveals that "hummingbird" is the most parsimonious ancestral state for the lower clade (plants D, E, F), that the ancestral states for the nodes in the top clade (plants A, B, C) are equivocal and that both "hummingbird" or "bee" pollinators are equally plausible for the pollination state at the root of the phylogeny. Supposing we have strong evidence from the fossil record that the root state is "hummingbird". Resolution of the root to "hummingbird" would yield the pattern of ancestral state reconstruction depicted by the symbols at the nodes with the state requiring the fewest changes circled.
Parsimony methods are intuitively appealing and highly efficient, such that they are still used in some cases to seed maximum likelihood optimization algorithms with an initial phylogeny.[21] However, the underlying assumption that evolution attained a certain end result as fast as possible is inaccurate. Natural selection and evolution do not work towards a goal, they simply select for or against randomly occurring genetic changes. Parsimony methods impose six general assumptions: that the phylogenetic tree you are using is correct, that you have all of the relevant data, in which no mistakes were made in coding, that all branches of the phylogenetic tree are equally likely to change, that the rate of evolution is slow, and that the chance of losing or gaining a characteristic is the same.[1] In reality, assumptions are often violated, leading to several issues:
- Variation in rates of evolution. Fitch's method assumes that changes between all character states are equally likely to occur; thus, any change incurs the same cost for a given tree. This assumption is often unrealistic and can limit the accuracy of such methods.[8] For example, transitions tend to occur more often than transversions in the evolution of nucleic acids. This assumption can be relaxed by assigning differential costs to specific character state changes, resulting in a weighted parsimony algorithm.[22]
- Rapid evolution. The upshot of the "minimum evolution" heuristic underlying such methods is that such methods assume that changes are rare, and thus are inappropriate in cases where change is the norm rather than the exception.[23][24]
- Variation in time among lineages. Parsimony methods implicitly assume that the same amount of evolutionary time has passed along every branch of the tree. Thus, they do not account for variation in branch lengths in the tree, which are often used to quantify the passage of evolutionary or chronological time. This limitation makes the technique liable to infer that one change occurred on a very short branch rather than multiple changes occurring on a very long branch, for example.[25] In addition, it is possible that some branches of the tree could be experiencing higher selection and change rates than others, perhaps due to changing environmental factors. Some periods of time may represent more rapid evolution than others, when this happens parsimony becomes inaccurate.[26] This shortcoming is addressed by model-based methods (both maximum likelihood and Bayesian methods) that infer the stochastic process of evolution as it unfolds along each branch of a tree.[27]
- Statistical justification. Without a statistical model underlying the method, its estimates do not have well-defined uncertainties.[23][25][28]
- Convergent evolution. When considering a single character state, parsimony will automatically assume that two organisms that share that characteristic will be more closely related than those who do not. For example, just because dogs and apes have fur does not mean that they are more closely related than apes are to humans.
Maximum likelihood
editMaximum likelihood (ML) methods of ancestral state reconstruction treat the character states at internal nodes of the tree as parameters, and attempt to find the parameter values that maximize the probability of the data (the observed character states) given the hypothesis (a model of evolution and a phylogeny relating the observed sequences or taxa). In other words, this method assumes that the ancestral states are those which are statistically most likely, given the observed phenotypes. Some of the earliest ML approaches to ancestral reconstruction were developed in the context of genetic sequence evolution;[29][30] similar models were also developed for the analogous case of discrete character evolution.[31]
The use of a model of evolution accounts for the fact that not all events are equally likely to happen. For example, a transition, which is a type of point mutation from one purine to another, or from one pyrimidine to another is much more likely to happen than a transversion, which is the chance of a purine being switched to a pyrimidine, or vice versa. These differences are not captured by maximum parsimony. However, just because some events are more likely than others does not mean that they always happen. We know that throughout evolutionary history there have been times when there was a large gap between what was most likely to happen, and what actually occurred. When this is the case, maximum parsimony may actually be more accurate because it is more willing to make large, unlikely leaps than maximum likelihood is. Maximum likelihood has been shown to be quite reliable in reconstructing character states, but it does not do as good of a job at giving accurate estimations of the stability of proteins. Maximum likelihood always overestimates the stability of proteins, which makes sense since it assumes that the proteins that were made and used were the most stable and optimal.[13] The merits of maximum likelihood have been subject to debate, with some having concluded that maximum likelihood test represents a good medium between accuracy and speed.[32] However, other studies have complained that maximum likelihood takes too much time and computational power to be useful in some scenarios.[33]
These approaches employ the same probabilistic framework as used to infer the phylogenetic tree.[34] In brief, the evolution of a genetic sequence is modelled by a time-reversible continuous time Markov process. In the simplest of these, all characters undergo independent state transitions (such as nucleotide substitutions) at a constant rate over time. This basic model is frequently extended to allow different rates on each branch of the tree. In reality, mutation rates may also vary over time (due, for example, to environmental changes); this can be modelled by allowing the rate parameters to evolve along the tree, at the expense of having an increased number of parameters. A model defines transition probabilities from states i to j along a branch of length t (in units of evolutionary time). The likelihood of a phylogeny is computed from a nested sum of transition probabilities that corresponds to the hierarchical structure of the proposed tree. At each node, the likelihood of its descendants is summed over all possible ancestral character states at that node:

where we are computing the likelihood of the subtree rooted at node x with direct descendants y and z, denotes the character state of the i-th node, is the branch length (evolutionary time) between nodes i and j, and is the set of all possible character states (for example, the nucleotides A, C, G, and T).[34] Thus, the objective of ancestral reconstruction is to find the assignment to for all x internal nodes that maximizes the likelihood of the observed data for a given tree.




Marginal and joint likelihood
editRather than compute the overall likelihood for alternative trees, the problem for ancestral reconstruction is to find the combination of character states at each ancestral node with the highest marginal maximum likelihood. Generally speaking, there are two approaches to this problem. First, one can assign the most likely character state to each ancestor independently of the reconstruction of all other ancestral states. This approach is referred to as marginal reconstruction. It is akin to summing over all combinations of ancestral states at all of the other nodes of the tree (including the root node), other than those for which data is available. Marginal reconstruction is finding the state at the current node that maximizes the likelihood integrating over all other states at all nodes, in proportion to their probability. Second, one may instead attempt to find the joint combination of ancestral character states throughout the tree which jointly maximizes the likelihood of the entire dataset. Thus, this approach is referred to as joint reconstruction.[29] Not surprisingly, joint reconstruction is more computationally complex than marginal reconstruction. Nevertheless, efficient algorithms for joint reconstruction have been developed with a time complexity that is generally linear with the number of observed taxa or sequences.[7]
ML-based methods of ancestral reconstruction tend to provide greater accuracy than MP methods in the presence of variation in rates of evolution among characters (or across sites in a genome).[35][36] However, these methods are not yet able to accommodate variation in rates of evolution over time, otherwise known as heterotachy. If the rate of evolution for a specific character accelerates on a branch of the phylogeny, then the amount of evolution that has occurred on that branch will be underestimated for a given length of the branch and assuming a constant rate of evolution for that character. In addition to that, it is difficult to distinguish heterotachy from variation among characters in rates of evolution.[37]
Since ML (unlike maximum parsimony) requires the investigator to specify a model of evolution, its accuracy may be affected by the use of a grossly incorrect model (model misspecification). Furthermore, ML can only provide a single reconstruction of character states (what is often referred to as a "point estimate") — when the likelihood surface is highly non-convex, comprising multiple peaks (local optima), then a single point estimate cannot provide an adequate representation, and a Bayesian approach may be more suitable.
Bayesian inference
editBayesian inference uses the likelihood of observed data to update the investigator's belief, or prior distribution, to yield the posterior distribution. In the context of ancestral reconstruction, the objective is to infer the posterior probabilities of ancestral character states at each internal node of a given tree. Moreover, one can integrate these probabilities over the posterior distributions over the parameters of the evolutionary model and the space of all possible trees. This can be expressed as an application of Bayes' theorem:

where S represents the ancestral states, D corresponds to the observed data, and represents both the evolutionary model and the phylogenetic tree. is the likelihood of the observed data which can be computed by Felsenstein's pruning algorithm as given above. is the prior probability of the ancestral states for a given model and tree. Finally, is the probability of the data for a given model and tree, integrated over all possible ancestral states.




Bayesian inference is the method that many have argued is the most accurate.[8] In general, Bayesian statistical methods allow investigators to combine pre-existing information with new hypothesis. In the case of evolution, it combines the likelihood of the data observed with the likelihood that the events happened in the order they did, while recognizing the potential for error and uncertainty. Overall, it is the most accurate method for reconstructing ancestral genetic sequences, as well as protein stability.[25] Unlike the other two methods, Bayesian inference yields a distribution of possible trees, allowing for more accurate and easily interpretable estimates of the variance of possible outcomes.[38]
We have given two formulations above to emphasize the two different applications of Bayes' theorem, which we discuss in the following section.
Empirical and hierarchical Bayes
editOne of the first implementations of a Bayesian approach to ancestral sequence reconstruction was developed by Yang and colleagues,[29] where the maximum likelihood estimates of the evolutionary model and tree, respectively, were used to define the prior distributions. Thus, their approach is an example of an empirical Bayes method to compute the posterior probabilities of ancestral character states; this method was first implemented in the software package PAML.[39] In terms of the above Bayesian rule formulation, the empirical Bayes method fixes to the empirical estimates of the model and tree obtained from the data, effectively dropping from the posterior likelihood, and prior terms of the formula. Moreover, Yang and colleagues[29] used the empirical distribution of site patterns (i.e., assignments of nucleotides to tips of the tree) in their alignment of observed nucleotide sequences in the denominator in place of exhaustively computing over all possible values of S given . Computationally, the empirical Bayes method is akin to the maximum likelihood reconstruction of ancestral states except that, rather than searching for the ML assignment of states based on their respective probability distributions at each internal node, the probability distributions themselves are reported directly.

Empirical Bayes methods for ancestral reconstruction require the investigator to assume that the evolutionary model parameters and tree are known without error. When the size or complexity of the data makes this an unrealistic assumption, it may be more prudent to adopt the fully hierarchical Bayesian approach and infer the joint posterior distribution over the ancestral character states, model, and tree.[40] Huelsenbeck and Bollback first proposed[40] a hierarchical Bayes method to ancestral reconstruction by using Markov chain Monte Carlo (MCMC) methods to sample ancestral sequences from this joint posterior distribution. A similar approach was also used to reconstruct the evolution of symbiosis with algae in fungal species (lichenization).[41] For example, the Metropolis-Hastings algorithm for MCMC explores the joint posterior distribution by accepting or rejecting parameter assignments on the basis of the ratio of posterior probabilities.
Put simply, the empirical Bayes approach calculates the probabilities of various ancestral states for a specific tree and model of evolution. By expressing the reconstruction of ancestral states as a set of probabilities, one can directly quantify the uncertainty for assigning any particular state to an ancestor. On the other hand, the hierarchical Bayes approach averages these probabilities over all possible trees and models of evolution, in proportion to how likely these trees and models are, given the data that has been observed.
Whether the hierarchical Bayes method confers a substantial advantage in practice remains controversial, however.[42] Moreover, this fully Bayesian approach is limited to analyzing relatively small numbers of sequences or taxa because the space of all possible trees rapidly becomes too vast, making it computationally infeasible for chain samples to converge in a reasonable amount of time.
Calibration
editAncestral reconstruction can be informed by the observed states in historical samples of known age, such as fossils or archival specimens. Since the accuracy of ancestral reconstruction generally decays with increasing time, the use of such specimens provides data that are closer to the ancestors being reconstructed and will most likely improve the analysis, especially when rates of character change vary through time. This concept has been validated by an experimental evolutionary study in which replicate populations of bacteriophage T7 were propagated to generate an artificial phylogeny.[43] In revisiting these experimental data, Oakley and Cunningham[44] found that maximum parsimony methods were unable to accurately reconstruct the known ancestral state of a continuous character (plaque size); these results were verified by computer simulation. This failure of ancestral reconstruction was attributed to a directional bias in the evolution of plaque size (from large to small plaque diameters) that required the inclusion of "fossilized" samples to address.
Studies of both mammalian carnivores[45] and fishes[46] have demonstrated that without incorporating fossil data, the reconstructed estimates of ancestral body sizes are unrealistically large. Moreover, Graham Slater and colleagues showed[47] using caniform carnivorans that incorporating fossil data into prior distributions improved both the Bayesian inference of ancestral states and evolutionary model selection, relative to analyses using only contemporaneous data.
Models
editMany models have been developed to estimate ancestral states of discrete and continuous characters from extant descendants.[48] Such models assume that the evolution of a trait through time may be modelled as a stochastic process. For discrete-valued traits (such as "pollinator type"), this process is typically taken to be a Markov chain; for continuous-valued traits (such as "brain size"), the process is frequently taken to be a Brownian motion or an Ornstein-Uhlenbeck process. Using this model as the basis for statistical inference, one can now use maximum likelihood methods or Bayesian inference to estimate the ancestral states.
Discrete-state models
editSuppose the trait in question may fall into one of states, labelled . The typical means of modelling evolution of this trait is via a continuous-time Markov chain, which may be briefly described as follows. Each state has associated to it rates of transition to all of the other states. The trait is modelled as stepping between the states; when it reaches a given state, it starts an exponential "clock" for each of the other states that it can step to. It then "races" the clocks against each other, and it takes a step towards the state whose clock is the first to ring. In such a model, the parameters are the transition rates , which can be estimated using, for example, maximum likelihood methods, where one maximizes over the set of all possible configurations of states of the ancestral nodes.




In order to recover the state of a given ancestral node in the phylogeny (call this node ) by maximum likelihood, the procedure is: find the maximum likelihood estimate of ; then compute the likelihood of each possible state for conditioning on ; finally, choose the ancestral state which maximizes this.[23] One may also use this substitution model as the basis for a Bayesian inference procedure, which would consider the posterior belief in the state of an ancestral node given some user-chosen prior.




Because such models may have as many as parameters, overfitting may be an issue. Some common choices that reduce the parameter space are:

- Markov -state 1 parameter model: this model is the reverse-in-time -state counterpart of the Jukes-Cantor model. In this model, all transitions have the same rate , regardless of their start and end states. Some transitions may be disallowed by declaring that their rates are simply 0; this may be the case, for example, if certain states cannot be reached from other states in a single transition.
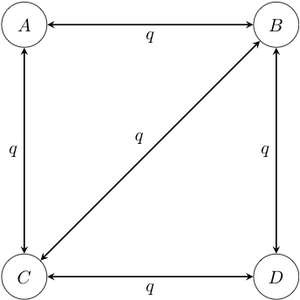
Example of a four-state 1-parameter Markov chain model. Note that in this diagram, transitions between states A and D have been disallowed; it is conventional to not draw the arrow rather than to draw it with a rate of 0. - Asymmetrical Markov -state 2 parameter model: in this model, the state space is ordered (so that, for example, state 1 is smaller than state 2, which is smaller than state 3), and transitions may only occur between adjacent states. This model contains two parameters and : one for the rate of increase of state (e.g. 0 to 1, 1 to 2, etc.), and one for the rate of decrease in state (e.g. from 2 to 1, 1 to 0, etc.).

Graphical representation of an asymmetrical five-state 2-parameter Markov chain model.





Example: Binary state speciation and extinction model
editThe binary state speciation and extinction model[49] (BiSSE) is a discrete-space model that does not directly follow the framework of those mentioned above. It allows estimation of ancestral binary character states jointly with diversification rates associated with different character states; it may also be straightforwardly extended to a more general multiple-discrete-state model. In its most basic form, this model involves six parameters: two speciation rates (one each for lineages in states 0 and 1); similarly, two extinction rates; and two rates of character change. This model allows for hypothesis testing on the rates of speciation/extinction/character change, at the cost of increasing the number of parameters.
Continuous-state models
editIn the case where the trait instead takes non-discrete values, one must instead turn to a model where the trait evolves as some continuous process. Inference of ancestral states by maximum likelihood (or by Bayesian methods) would proceed as above, but with the likelihoods of transitions in state between adjacent nodes given by some other continuous probability distribution.





- Brownian motion: in this case, if nodes and are adjacent in the phylogeny (say is the ancestor of ) and separated by a branch of length , the likelihood of a transition from being in state to being in state is given by a Gaussian density with mean and variance In this case, there is only one parameter ( ), and the model assumes that the trait evolves freely without a bias toward increase or decrease, and that the rate of change is constant throughout the branches of the phylogenetic tree.[50]
- Ornstein-Uhlenbeck process: in brief, an Ornstein-Uhlenbeck process is a continuous stochastic process that behaves like a Brownian motion, but attracted toward some central value, where the strength of the attraction increases with the distance from that value.[51][52][53] This is useful for modelling scenarios where the trait is subject to stabilizing selection around a certain value (say ). Under this model, the above-described transition of being in state to being in state would have a likelihood defined by the transition density of an Ornstein-Uhlenbeck process with two parameters: , which describes the variance of the driving Brownian motion, and , which describes the strength of its attraction to . As tends to , the process is less and less constrained by its attraction to and the process becomes a Brownian motion. Because of this, the models may be nested, and log-likelihood ratio tests discerning which of the two models is appropriate may be carried out.[50]
- Stable models of continuous character evolution:[54] though Brownian motion is appealing and tractable as a model of continuous evolution, it does not permit non-neutrality in its basic form, nor does it provide for any variation in the rate of evolution over time. Instead, one may use a stable process, one whose values at fixed times are distributed as stable distributions, to model the evolution of traits. Stable processes, roughly speaking, behave as Brownian motions that also incorporate discontinuous jumps. This allows to appropriately model scenarios in which short bursts of fast trait evolution are expected. In this setting, maximum likelihood methods are poorly suited due to a rugged likelihood surface and because the likelihood may be made arbitrarily large, so Bayesian methods are more appropriate.[54]







Applications
editCharacter evolution
editAncestral reconstruction is widely used to infer the ecological, phenotypic, or biogeographic traits associated with ancestral nodes in a phylogenetic tree. All methods of ancestral trait reconstructions have pitfalls, as they use mathematical models to predict how traits have changed with large amounts of missing data. This missing data includes the states of extinct species, the relative rates of evolutionary changes, knowledge of initial character states, and the accuracy of phylogenetic trees. In all cases where ancestral trait reconstruction is used, findings should be justified with an examination of the biological data that supports model based conclusions. Griffith O.W. et al.[55]
Ancestral reconstruction allows for the study of evolutionary pathways, adaptive selection, developmental gene expression,[56][57] and functional divergence of the evolutionary past. For a review of biological and computational techniques of ancestral reconstruction see Chang et al..[58] For criticism of ancestral reconstruction computation methods see Williams P.D. et al..[13]
Behavior and life history evolution
editIn horned lizards (genus Phrynosoma), viviparity (live birth) has evolved multiple times, based on ancestral reconstruction methods.[59]
Diet reconstruction in Galapagos finches
editBoth phylogenetic and character data are available for the radiation of finches inhabiting the Galapagos Islands. These data allow testing of hypotheses concerning the timing and ordering of character state changes through time via ancestral state reconstruction. During the dry season, the diets of the 13 species of Galapagos finches may be assorted into three broad diet categories, first those that consume grain-like foods are considered "granivores", those that ingest arthropods are termed "insectivores" and those that consume vegetation are classified as "folivores".[23] Dietary ancestral state reconstruction using maximum parsimony recover 2 major shifts from an insectivorous state: one to granivory, and one to folivory. Maximum-likelihood ancestral state reconstruction recovers broadly similar results, with one significant difference: the common ancestor of the tree finch (Camarhynchus) and ground finch (Geospiza) clades are most likely granivorous rather than insectivorous (as judged by parsimony). In this case, this difference between ancestral states returned by maximum parsimony and maximum likelihood likely occurs as a result of the fact that ML estimates consider branch lengths of the phylogenetic tree.[23]
Morphological and physiological character evolution
editPhrynosomatid lizards show remarkable morphological diversity, including in the relative muscle fiber type composition in their hindlimb muscles. Ancestor reconstruction based on squared-change parsimony (equivalent to maximum likelihood under Brownian motion character evolution[60]) indicates that horned lizards, one of the three main subclades of the lineage, have undergone a major evolutionary increase in the proportion of fast-oxidative glycolytic fibers in their iliofibularis muscles.[61]
Mammalian body mass
editIn an analysis of the body mass of 1,679 placental mammal species comparing stable models of continuous character evolution to Brownian motion models, Elliot and Mooers[54] showed that the evolutionary process describing mammalian body mass evolution is best characterized by a stable model of continuous character evolution, which accommodates rare changes of large magnitude. Under a stable model, ancestral mammals retained a low body mass through early diversification, with large increases in body mass coincident with the origin of several Orders of large body massed species (e.g. ungulates). By contrast, simulation under a Brownian motion model recovered a less realistic, order of magnitude larger body mass among ancestral mammals, requiring significant reductions in body size prior to the evolution of Orders exhibiting small body size (e.g. Rodentia). Thus stable models recover a more realistic picture of mammalian body mass evolution by permitting large transformations to occur on a small subset of branches.[54]
Correlated character evolution
editPhylogenetic comparative methods (inferences drawn through comparison of related taxa) are often used to identify biological characteristics that do not evolve independently, which can reveal an underlying dependence. For example, the evolution of the shape of a finch's beak may be associated with its foraging behaviour. However, it is not advisable to search for these associations by the direct comparison of measurements or genetic sequences because these observations are not independent because of their descent from common ancestors. For discrete characters, this problem was first addressed in the framework of maximum parsimony by evaluating whether two characters tended to undergo a change on the same branches of the tree.[62][63] Felsenstein identified this problem for continuous character evolution and proposed a solution similar to ancestral reconstruction, in which the phylogenetic structure of the data was accommodated statistically by directing the analysis through computation of "independent contrasts" between nodes of the tree related by non-overlapping branches.[28]
Molecular evolution
editOn a molecular level, amino acid residues at different locations of a protein may evolve non-independently because they have a direct physicochemical interaction, or indirectly by their interactions with a common substrate or through long-range interactions in the protein structure. Conversely, the folded structure of a protein could potentially be inferred from the distribution of residue interactions.[64] One of the earliest applications of ancestral reconstruction, to predict the three-dimensional structure of a protein through residue contacts, was published by Shindyalov and colleagues.[65] Phylogenies relating 67 different protein families were generated by a distance-based clustering method (unweighted pair group method with arithmetic mean, UPGMA), and ancestral sequences were reconstructed by parsimony. The authors reported a weak but significant tendency for co-evolving pairs of residues to be co-located in the known three-dimensional structure of the proteins.
The reconstruction of ancient proteins and DNA sequences has only recently become a significant scientific endeavour. The developments of extensive genomic sequence databases in conjunction with advances in biotechnology and phylogenetic inference methods have made ancestral reconstruction cheap, fast, and scientifically practical. This concept has been applied to identify co-evolving residues in protein sequences using more advanced methods for the reconstruction of phylogenies and ancestral sequences. For example, ancestral reconstruction has been used to identify co-evolving residues in proteins encoded by RNA virus genomes, particularly in HIV.[66][67][68]
Ancestral protein and DNA reconstruction allows for the recreation of protein and DNA evolution in the laboratory so that it can be studied directly.[58] With respect to proteins, this allows for the investigation of the evolution of present-day molecular structure and function. Additionally, ancestral protein reconstruction can lead to the discoveries of new biochemical functions that have been lost in modern proteins.[69][70] It also allows insights into the biology and ecology of extinct organisms.[71] Although the majority of ancestral reconstructions have dealt with proteins, it has also been used to test evolutionary mechanisms at the level of bacterial genomes[72] and primate gene sequences.[73]
Vaccine design
editRNA viruses such as the human immunodeficiency virus (HIV) evolve at an extremely rapid rate, orders of magnitude faster than mammals or birds. For these organisms, ancestral reconstruction can be applied on a much shorter time scale; for example, in order to reconstruct the global or regional progenitor of an epidemic that has spanned decades rather than millions of years. A team around Brian Gaschen proposed[74] that such reconstructed strains be used as targets for vaccine design efforts, as opposed to sequences isolated from patients in the present day. Because HIV is extremely diverse, a vaccine designed to work on one patient's viral population might not work for a different patient, because the evolutionary distance between these two viruses may be large. However, their most recent common ancestor is closer to each of the two viruses than they are to each other. Thus, a vaccine designed for a common ancestor could have a better chance of being effective for a larger proportion of circulating strains. Another team took this idea further by developing a center-of-tree reconstruction method to produce a sequence whose total evolutionary distance to contemporary strains is as small as possible.[75] Strictly speaking, this method was not ancestral reconstruction, as the center-of-tree (COT) sequence does not necessarily represent a sequence that has ever existed in the evolutionary history of the virus. However, Rolland and colleagues did find that, in the case of HIV, the COT virus was functional when synthesized. Similar experiments with synthetic ancestral sequences obtained by maximum likelihood reconstruction have likewise shown that these ancestors are both functional and immunogenic,[76][77] lending some credibility to these methods. Furthermore, ancestral reconstruction can potentially be used to infer the genetic sequence of the transmitted HIV variants that have gone on to establish the next infection, with the objective of identifying distinguishing characteristics of these variants (as a non-random selection of the transmitted population of viruses) that may be targeted for vaccine design.[78]
Genome rearrangements
editRather than inferring the ancestral DNA sequence, one may be interested in the larger-scale molecular structure and content of an ancestral genome. This problem is often approached in a combinatorial framework, by modelling genomes as permutations of genes or homologous regions. Various operations are allowed on these permutations, such as an inversion (a segment of the permutation is reversed in-place), deletion (a segment is removed), transposition (a segment is removed from one part of the permutation and spliced in somewhere else), or gain of genetic content through recombination, duplication or horizontal gene transfer. The "genome rearrangement problem", first posed by Watterson and colleagues,[17] asks: given two genomes (permutations) and a set of allowable operations, what is the shortest sequence of operations that will transform one genome into the other? A generalization of this problem applicable to ancestral reconstruction is the "multiple genome rearrangement problem":[79] given a set of genomes and a set of allowable operations, find (i) a binary tree with the given genomes as its leaves, and (ii) an assignment of genomes to the internal nodes of the tree, such that the total number of operations across the whole tree is minimized. This approach is similar to parsimony, except that the tree is inferred along with the ancestral sequences. Unfortunately, even the single genome rearrangement problem is NP-hard,[80] although it has received much attention in mathematics and computer science (for a review, see Fertin and colleagues[81]).
The reconstruction of ancestral genomes is also called karyotype reconstruction. Chromosome painting is currently the main experimental technique.[82][83] Recently, researchers have developed computational methods to reconstruct the ancestral karyotype by taking advantage of comparative genomics.[84][85] Furthermore, comparative genomics and ancestral genome reconstruction has been applied to identify ancient horizontal gene transfer events at the last common ancestor of a lineage (e.g. Candidatus Accumulibacter phosphatis[86]) to identify the evolutionary basis for trait acquisition.
Spatial applications
editMigration
editAncestral reconstruction is not limited to biological traits. Spatial location is also a trait, and ancestral reconstruction methods can infer the locations of ancestors of the individuals under consideration. Such techniques were used by Lemey and colleagues[16] to geographically trace the ancestors of 192 Avian influenza A-H5N1 strains sampled from twenty localities in Europe and Asia, and for 101 rabies virus sequences sampled across twelve African countries.
Treating locations as discrete states (countries, cities, etc.) allows for the application of the discrete-state models described above. However, unlike in a model where the state space for the trait is small, there may be many locations, and transitions between certain pairs of states may rarely or never occur; for example, migration between distant locales may never happen directly if air travel between the two places does not exist, so such migrations must pass through intermediate locales first. This means that there could be many parameters in the model which are zero or close to zero. To this end, Lemey and colleagues used a Bayesian procedure to not only estimate the parameters and ancestral states, but also to select which migration parameters are not zero; their work suggests that this procedure does lead to more efficient use of the data. They also explore the use of prior distributions that incorporate geographical structure or hypotheses about migration dynamics, finding that those they considered had little effect on the findings.
Using this analysis, the team around Lemey found that the most likely hub of diffusion of A-H5N1 is Guangdong, with Hong Kong also receiving posterior support. Further, their results support the hypothesis of long-standing presence of African rabies in West Africa.
Species ranges
editInferring historical biogeographic patterns often requires reconstructing ancestral ranges of species on phylogenetic trees.[87] For instance, a well-resolved phylogeny of plant species in the genus Cyrtandra[87] was used together with information of their geographic ranges to compare four methods of ancestral range reconstruction. The team compared Fitch parsimony,[20] (FP; parsimony) stochastic mapping[88] (SM; maximum likelihood), dispersal-vicariance analysis[89] (DIVA; parsimony), and dispersal-extinction-cladogenesis[15][90] (DEC; maximum-likelihood). Results indicated that both parsimony methods performed poorly, which was likely due to the fact that parsimony methods do not consider branch lengths. Both maximum-likelihood methods performed better; however, DEC analyses that additionally allow incorporation of geological priors gave more realistic inferences about range evolution in Cyrtandra relative to other methods.[87]
Another maximum likelihood method recovers the phylogeographic history of a gene[91] by reconstructing the ancestral locations of the sampled taxa. This method assumes a spatially explicit random walk model of migration to reconstruct ancestral locations given the geographic coordinates of the individuals represented by the tips of the phylogenetic tree. When applied to a phylogenetic tree of chorus frogs Pseudacris feriarum, this method recovered recent northward expansion, higher per-generation dispersal distance in the recently colonized region, a non-central ancestral location, and directional migration.[91]

The first consideration of the multiple genome rearrangement problem, long before its formalization in terms of permutations, was presented by Sturtevant and Dobzhansky in 1936.[92] They examined genomes of several strains of fruit fly from different geographic locations, and observed that one configuration, which they called "standard", was the most common throughout all the studied areas. Remarkably, they also noticed that four different strains could be obtained from the standard sequence by a single inversion, and two others could be related by a second inversion. This allowed them to hypothesize a phylogeny for the sequences, and to infer that the standard sequence was probably also the ancestral one.
Linguistic Evolution
editReconstructions of the words and phenomes of ancient proto-languages such as Proto-Indo-European have been performed based on the observed analogues in present-day languages. Typically, these analyses are carried out manually using the "comparative method".[93] First, words from different languages with a common etymology (cognates) are identified in the contemporary languages under study, analogous to the identification of orthologous biological sequences. Second, correspondences between individual sounds in the cognates are identified, a step similar to biological sequence alignment, although performed manually. Finally, likely ancestral sounds are hypothesised by manual inspection and various heuristics (such as the fact that most languages have both nasal and non-nasal vowels).[93]
Software
editThere are many software packages available which can perform ancestral state reconstruction. Generally, these software packages have been developed and maintained through the efforts of scientists in related fields and released under free software licenses. The following table is not meant to be a comprehensive itemization of all available packages, but provides a representative sample of the extensive variety of packages that implement methods of ancestral reconstruction with different strengths and features.
| Name | Methods | Platform | Inputs | ! Character Types | Continuous (C) or Discrete Characters (D) | Software License |
|---|---|---|---|---|---|---|
| PAML | Maximum Likelihood | Unix, Mac, Win | PHYLIP, NEXUS, FASTA | Nucleotide, Protein | D | GNU General Public License, version 3 |
| BEAST | Bayesian | Unix, Mac, Win | NEXUS, BEAST XML | Nucleotide, Protein, Geographic | C, D | GNU Lesser General Public License |
| phytools | Maximum Likelihood | Unix, Mac, Win | newick, nexus | Qualitative and quantitative traits | C, D | GNU General Public License |
| APE | Maximum Likelihood | Unix, Mac, Win | NEXUS, FASTA, CLUSTAL | Nucleotide, Protein | C, D | GNU General Public License |
| Diversitree | Maximum Likelihood | Unix, Mac, Win | NEXUS | Qualitative and quantitative traits, Geographic | C, D | GNU General Public License, version 2 |
| HyPhy | Maximum Likelihood | Unix, Mac, Win | MEGA, NEXUS, FASTA, PHYLIP | Nucleotide, Protein (customizable) | D | GNU Free Documentation License 1.3 |
| BayesTraits | Bayesian | Unix, Mac, Win | TSV or space delimited table. Rows are species, columns are traits. | Qualitative and quantitative traits | C, D | Creative Commons Attribution License |
| Lagrange | Maximum Likelihood | Linux, Mac, Win | TSV/CSV of species regions. Rows are species and columns are geographic regions | Geographic | - | GNU General Public License, version 2 |
| Mesquite | Parsimony, Maximum Likelihood | Unix, Mac, Win | Fasta, NBRF, Genbank, PHYLIP, CLUSTAL, TSV | Nucleotide, Protein, Geographic | C, D | Creative Commons Attribution 3.0 License |
| Phylomapper | Maximum Likelihood, Bayesian (as of version 2) | Unix, Mac, Win | NEXUS | Geographic, Ecological niche | C, D | - |
| Ancestors | Maximum Likelihood | Web | Fasta | Nucleotide (indels) | D | - |
| Phyrex | Maximum Parsimony | Linux | Fasta | Gene expression | C, D | Proprietary |
| SIMMAP | Stochastic Mapping | Mac | XML-like format | Nucleotide, qualitative traits | D | Proprietary |
| MrBayes | Bayesian | Unix, Mac, Win | NEXUS | Nucleotide, Protein | D | GNU General Public License |
| PARANA | Maximum Parsimony | Unix, Mac, Win | Newick | Biological networks | D | Apache License |
| PHAST (PREQUEL) | Maximum Likelihood | Unix, Mac, Win | Multiple Alignment | Nucleotide | D | BSD License |
| RASP | Maximum Likelihood, Bayesian | Unix, Mac, Win | Newick | Geographic | D | - |
| VIP | Maximum Parsimony | Linux, Win | Newick | Geographic | D (grid) | GPL Creative Commons |
| FastML | Maximum Likelihood | Web, Unix | Fasta | Nucleotide, Protein | D | Copyright |
| MLGO | Maximum likelihood | Web | Custom | Gene order permutation | D | GNU |
| BADGER | Bayesian | Unix, Mac, Win | Custom | Gene order permutation | D | GNU GPL version 2 |
| COUNT | Maximum Parsimony, maximum likelihood | Unix, Mac, Win | Tab-delimited text file of rows for taxa and count data in columns. | Count (numerical) data (e.g., homolog family size) | D | BSD |
| MEGA | Maximum parsimony, maximum likelihood. | Mac, Win | MEGA | Nucleotide, Protein | D | Proprietary |
| ANGES | Local Parsimony | Unix | Custom | Genome maps | D | GNU General Public License, version 3 |
| DECIPHER | Maximum Likelihood | Unix, Mac, Win | FASTA, GenBank | Nucleotide | D | GNU General Public License, version 3 |
| EREM | Maximum likelihood. | Win, Unix, Matlab module | Custom text format for model parameters, tree, observed character values. | Binary | D | None specified, although site indicates software is freely available. |
Package descriptions
editMolecular evolution
editThe majority of these software packages are designed for analyzing genetic sequence data. For example, PAML[94] is a collection of programs for the phylogenetic analysis of DNA and protein sequence alignments by maximum likelihood. Ancestral reconstruction can be performed using the codeml program. In addition, LAZARUS is a collection of Python scripts that wrap the ancestral reconstruction functions of PAML for batch processing and greater ease-of-use.[95] Software packages such as MEGA, HyPhy, and Mesquite also perform phylogenetic analysis of sequence data, but are designed to be more modular and customizable. HyPhy[96] implements a joint maximum likelihood method of ancestral sequence reconstruction[7] that can be readily adapted to reconstructing a more generalized range of discrete ancestral character states such as geographic locations by specifying a customized model in its batch language. Mesquite[97] provides ancestral state reconstruction methods for both discrete and continuous characters using both maximum parsimony and maximum likelihood methods. It also provides several visualization tools for interpreting the results of ancestral reconstruction. MEGA[98] is a modular system, too, but places greater emphasis on ease-of-use than customization of analyses. As of version 5, MEGA allows the user to reconstruct ancestral states using maximum parsimony, maximum likelihood, and empirical Bayes methods.[98]
The Bayesian analysis of genetic sequences may confer greater robustness to model misspecification. MrBayes[99] allows inference of ancestral states at ancestral nodes using the full hierarchical Bayesian approach. The PREQUEL program distributed in the PHAST package[100] performs comparative evolutionary genomics using ancestral sequence reconstruction. SIMMAP[101] stochastically maps mutations on phylogenies. BayesTraits[31] analyses discrete or continuous characters in a Bayesian framework to evaluate models of evolution, reconstruct ancestral states, and detect correlated evolution between pairs of traits.
Other character types
editOther software packages are more oriented towards the analysis of qualitative and quantitative traits (phenotypes). For example, the ape package[102] in the statistical computing environment R also provides methods for ancestral state reconstruction for both discrete and continuous characters through the 'ace' function, including maximum likelihood. Phyrex implements a maximum parsimony-based algorithm to reconstruct ancestral gene expression profiles, in addition to a maximum likelihood method for reconstructing ancestral genetic sequences (by wrapping around the baseml function in PAML).[103]
Several software packages also reconstruct phylogeography. BEAST (Bayesian Evolutionary Analysis by Sampling Trees)[104] and BEAST 2 provides tools for reconstructing ancestral geographic locations from observed sequences annotated with location data using Bayesian MCMC sampling methods. Diversitree[105] is an R package providing methods for ancestral state reconstruction under Mk2 (a continuous time Markov model of binary character evolution).[106] and BiSSE (Binary State Speciation and Extinction) models. Lagrange performs analyses on reconstruction of geographic range evolution on phylogenetic trees.[15] Phylomapper[91] is a statistical framework for estimating historical patterns of gene flow and ancestral geographic locations. RASP[107] infers ancestral states using statistical dispersal-vicariance analysis, Lagrange, Bayes-Lagrange, BayArea and BBM methods. VIP[108] infers historical biogeography by examining disjunct geographic distributions.
Genome rearrangements provide valuable information in comparative genomics between species. ANGES[109] compares extant related genomes through ancestral reconstruction of genetic markers. BADGER[110] uses a Bayesian approach to examining the history of gene rearrangement. Count[111] reconstructs the evolution of the size of gene families. EREM[112] analyses the gain and loss of genetic features encoded by binary characters. PARANA[113] performs parsimony based inference of ancestral biological networks that represent gene loss and duplication.
Web applications
editFinally, there are several web-server based applications that allow investigators to use maximum likelihood methods for ancestral reconstruction of different character types without having to install any software. For example, Ancestors[114] is web-server for ancestral genome reconstruction by the identification and arrangement of syntenic regions. FastML[115] is a web-server for probabilistic reconstruction of ancestral sequences by maximum likelihood that uses a gap character model for reconstructing indel variation. MLGO[116] is a web-server for maximum likelihood gene order analysis.
Future directions
editThe development and application of computational algorithms for ancestral reconstruction continues to be an active area of research across disciplines. For example, the reconstruction of sequence insertions and deletions (indels) has lagged behind the more straightforward application of substitution models. Bouchard-Côté and Jordan recently described a new model (the Poisson Indel Process)[117] which represents an important advance on the archetypal Thorne-Kishino-Felsenstein model of indel evolution.[118] In addition, the field is being driven forward by rapid advances in the area of next-generation sequencing technology, where sequences are generated from millions of nucleic acid templates by extensive parallelization of sequencing reactions in a custom apparatus. These advances have made it possible to generate a "deep" snapshot of the genetic composition of a rapidly evolving population, such as RNA viruses[119] or tumour cells,[120] in a relatively short amount of time. At the same time, the massive amount of data and platform-specific sequencing error profiles has created new bioinformatic challenges for processing these data for ancestral sequence reconstruction.
See also
editReferences
edit![]() This article was adapted from the following source under a CC BY 4.0 license (2015) (reviewer reports):
Jeffrey B Joy; Richard H Liang; Rosemary M McCloskey; T Nguyen; Art Poon (12 July 2016). "Ancestral Reconstruction". PLOS Computational Biology. 12 (7): e1004763. doi:10.1371/JOURNAL.PCBI.1004763. ISSN 1553-734X. PMC 4942178. PMID 27404731. Wikidata Q28596371.
This article was adapted from the following source under a CC BY 4.0 license (2015) (reviewer reports):
Jeffrey B Joy; Richard H Liang; Rosemary M McCloskey; T Nguyen; Art Poon (12 July 2016). "Ancestral Reconstruction". PLOS Computational Biology. 12 (7): e1004763. doi:10.1371/JOURNAL.PCBI.1004763. ISSN 1553-734X. PMC 4942178. PMID 27404731. Wikidata Q28596371.
- ^ a b Omland KE (1999). "The Assumptions and Challenges of Ancestral State Reconstructions". Systematic Biology. 48 (3): 604–611. doi:10.1080/106351599260175. ISSN 1063-5157.
- ^ Cai W, Pei J, Grishin NV (September 2004). "Reconstruction of ancestral protein sequences and its applications". BMC Evolutionary Biology. 4 (1): 33. doi:10.1186/1471-2148-4-33. PMC 522809. PMID 15377393.
- ^ Platnick NI, Cameron HD (1977). "Cladistic Methods in Textual, Linguistic, and Phylogenetic Analysis". Systematic Zoology. 26 (4): 380–385. doi:10.2307/2412794. ISSN 0039-7989. JSTOR 2412794.
- ^ Tehrani JJ (2013). "The phylogeny of Little Red Riding Hood". PLOS ONE. 8 (11): e78871. Bibcode:2013PLoSO...878871T. doi:10.1371/journal.pone.0078871. PMC 3827309. PMID 24236061.
- ^ Walker RS, Hill KR, Flinn MV, Ellsworth RM (April 2011). "Evolutionary history of hunter-gatherer marriage practices". PLOS ONE. 6 (4): e19066. Bibcode:2011PLoSO...619066W. doi:10.1371/journal.pone.0019066. PMC 3083418. PMID 21556360.
- ^ Brooks DR (1999). "Phylogenies and the Comparative Method in Animal Behavior, Edited by Emı̀ia P. Martins, Oxford University Press, 1996. X+415 pp". Behavioural Processes. 47 (2): 135–136. doi:10.1016/S0376-6357(99)00038-8. ISSN 0376-6357. PMID 24896936. S2CID 9872907.
- ^ a b c Pupko T, Pe'er I, Shamir R, Graur D (June 2000). "A fast algorithm for joint reconstruction of ancestral amino acid sequences". Molecular Biology and Evolution. 17 (6): 890–896. doi:10.1093/oxfordjournals.molbev.a026369. PMID 10833195.
- ^ a b c Pagel M, Meade A, Barker D (October 2004). "Bayesian estimation of ancestral character states on phylogenies". Systematic Biology. 53 (5): 673–684. CiteSeerX 10.1.1.483.4931. doi:10.1080/10635150490522232. PMID 15545248.
- ^ Sanger F, Thompson EO, Kitai R (March 1955). "The amide groups of insulin". The Biochemical Journal. 59 (3): 509–518. doi:10.1042/bj0590509. PMC 1216278. PMID 14363129.
- ^ Pauling L, Zuckerkandl E, Henriksen T, Lövstad R (1963). "Chemical Paleogenetics. Molecular "Restoration Studies" of Extinct Forms of Life". Acta Chemica Scandinavica. 17 (suplement): 9–16. doi:10.3891/acta.chem.scand.17s-0009. ISSN 0904-213X.
- ^ a b Dobzhansky T, Sturtevant AH (January 1938). "Inversions in the Chromosomes of Drosophila Pseudoobscura". Genetics. 23 (1): 28–64. doi:10.1093/genetics/23.1.28. PMC 1209001. PMID 17246876.
- ^ Harms MJ, Thornton JW (June 2010). "Analyzing protein structure and function using ancestral gene reconstruction". Current Opinion in Structural Biology. 20 (3): 360–366. doi:10.1016/j.sbi.2010.03.005. PMC 2916957. PMID 20413295.
- ^ a b c d Williams PD, Pollock DD, Blackburne BP, Goldstein RA (June 2006). "Assessing the accuracy of ancestral protein reconstruction methods". PLOS Computational Biology. 2 (6): e69. Bibcode:2006PLSCB...2...69W. doi:10.1371/journal.pcbi.0020069. PMC 1480538. PMID 16789817.
- ^ Ronquist F (September 2004). "Bayesian inference of character evolution". Trends in Ecology & Evolution. 19 (9): 475–481. doi:10.1016/j.tree.2004.07.002. PMID 16701310.
- ^ a b c Ree RH, Smith SA (February 2008). "Maximum likelihood inference of geographic range evolution by dispersal, local extinction, and cladogenesis". Systematic Biology. 57 (1): 4–14. CiteSeerX 10.1.1.457.2776. doi:10.1080/10635150701883881. PMID 18253896.
- ^ a b Lemey P, Rambaut A, Drummond AJ, Suchard MA (September 2009). "Bayesian phylogeography finds its roots". PLOS Computational Biology. 5 (9): e1000520. Bibcode:2009PLSCB...5E0520L. doi:10.1371/journal.pcbi.1000520. PMC 2740835. PMID 19779555.
- ^ a b Watterson GA, Ewens WJ, Hall TE, Morgan A (1982). "The chromosome inversion problem". Journal of Theoretical Biology. 99 (1): 1–7. Bibcode:1982JThBi..99....1W. doi:10.1016/0022-5193(82)90384-8. ISSN 0022-5193.
- ^ Tuffley C, Steel M (May 1997). "Links between maximum likelihood and maximum parsimony under a simple model of site substitution". Bulletin of Mathematical Biology. 59 (3): 581–607. CiteSeerX 10.1.1.22.6143. doi:10.1007/BF02459467. PMID 9172826. S2CID 189885872.
- ^ Swofford DL, Maddison WP (1987). "Reconstructing ancestral character states under Wagner parsimony". Mathematical Biosciences. 87 (2): 199–229. doi:10.1016/0025-5564(87)90074-5. ISSN 0025-5564.
- ^ a b Fitch WM (1971). "Toward Defining the Course of Evolution: Minimum Change for a Specific Tree Topology". Systematic Zoology. 20 (4): 406–416. doi:10.2307/2412116. ISSN 0039-7989. JSTOR 2412116.
- ^ Stamatakis A (November 2006). "RAxML-VI-HPC: maximum likelihood-based phylogenetic analyses with thousands of taxa and mixed models" (PDF). Bioinformatics. 22 (21): 2688–2690. doi:10.1093/bioinformatics/btl446. PMID 16928733.
- ^ Sankoff D (1975). "Minimal Mutation Trees of Sequences". SIAM Journal on Applied Mathematics. 28 (1): 35–42. CiteSeerX 10.1.1.665.9596. doi:10.1137/0128004. ISSN 0036-1399.
- ^ a b c d e Schluter D, Price T, Mooers AØ, Ludwig D (December 1997). "Likelihood of Ancestor States in Adaptive Radiation". Evolution; International Journal of Organic Evolution. 51 (6): 1699–1711. doi:10.2307/2410994. JSTOR 2410994. PMID 28565128.
- ^ Felsenstein J (1973). "Maximum Likelihood and Minimum-Steps Methods for Estimating Evolutionary Trees from Data on Discrete Characters". Systematic Zoology. 22 (3): 240–249. doi:10.2307/2412304. ISSN 0039-7989. JSTOR 2412304.
- ^ a b c Cunningham CW, Omland KE, Oakley TH (September 1998). "Reconstructing ancestral character states: a critical reappraisal". Trends in Ecology & Evolution. 13 (9): 361–366. Bibcode:1998TEcoE..13..361C. doi:10.1016/S0169-5347(98)01382-2. PMID 21238344. S2CID 6779286.
- ^ Mooers AØ, Schluter D (1999). "Reconstructing Ancestor States with Maximum Likelihood: Support for One- and Two-Rate Models". Systematic Biology. 48 (3): 623–633. CiteSeerX 10.1.1.594.175. doi:10.1080/106351599260193. ISSN 1063-5157.
- ^ Li G, Steel M, Zhang L (August 2008). "More taxa are not necessarily better for the reconstruction of ancestral character states". Systematic Biology. 57 (4): 647–653. arXiv:0803.0195. doi:10.1080/10635150802203898. PMID 18709600. S2CID 1373201.
- ^ a b Felsenstein J (1985). "Phylogenies and the Comparative Method". The American Naturalist. 125 (1): 1–15. doi:10.1086/284325. ISSN 0003-0147. S2CID 9731499.
- ^ a b c d Yang Z, Kumar S, Nei M (December 1995). "A new method of inference of ancestral nucleotide and amino acid sequences". Genetics. 141 (4): 1641–1650. doi:10.1093/genetics/141.4.1641. PMC 1206894. PMID 8601501.
- ^ Koshi JM, Goldstein RA (February 1996). "Probabilistic reconstruction of ancestral protein sequences". Journal of Molecular Evolution. 42 (2): 313–320. Bibcode:1996JMolE..42..313K. CiteSeerX 10.1.1.1031.2646. doi:10.1007/BF02198858. PMID 8919883. S2CID 15997589.
- ^ a b Pagel M (1999). "The Maximum Likelihood Approach to Reconstructing Ancestral Character States of Discrete Characters on Phylogenies". Systematic Biology. 48 (3): 612–622. doi:10.1080/106351599260184. ISSN 1063-5157.
- ^ Guindon S, Gascuel O (October 2003). "A simple, fast, and accurate algorithm to estimate large phylogenies by maximum likelihood". Systematic Biology. 52 (5): 696–704. CiteSeerX 10.1.1.110.5852. doi:10.1080/10635150390235520. PMID 14530136.
- ^ Doornik JA, Ooms M (2003). "Computational aspects of maximum likelihood estimation of autoregressive fractionally integrated moving average models". Computational Statistics & Data Analysis. 42 (3): 333–348. doi:10.1016/S0167-9473(02)00212-8. ISSN 0167-9473.
- ^ a b Felsenstein J (1981). "Evolutionary trees from DNA sequences: a maximum likelihood approach". Journal of Molecular Evolution. 17 (6): 368–376. Bibcode:1981JMolE..17..368F. doi:10.1007/BF01734359. PMID 7288891. S2CID 8024924.
- ^ Eyre-Walker A (December 1998). "Problems with parsimony in sequences of biased base composition". Journal of Molecular Evolution. 47 (6): 686–690. Bibcode:1998JMolE..47..686E. doi:10.1007/PL00006427. PMID 9847410. S2CID 26128712.
- ^ Pupko T, Pe'er I, Hasegawa M, Graur D, Friedman N (August 2002). "A branch-and-bound algorithm for the inference of ancestral amino-acid sequences when the replacement rate varies among sites: Application to the evolution of five gene families". Bioinformatics. 18 (8): 1116–1123. doi:10.1093/bioinformatics/18.8.1116. PMID 12176835.
- ^ Gruenheit N, Lockhart PJ, Steel M, Martin W (July 2008). "Difficulties in testing for covarion-like properties of sequences under the confounding influence of changing proportions of variable sites". Molecular Biology and Evolution. 25 (7): 1512–1520. doi:10.1093/molbev/msn098. hdl:10092/2637. PMID 18424773.
- ^ Huelsenbeck JP, Ronquist F (August 2001). "MRBAYES: Bayesian inference of phylogenetic trees". Bioinformatics. 17 (8): 754–755. doi:10.1093/bioinformatics/17.8.754. PMID 11524383.
- ^ Yang Z (October 1997). "PAML: a program package for phylogenetic analysis by maximum likelihood". Computer Applications in the Biosciences. 13 (5): 555–556. doi:10.1093/bioinformatics/13.5.555. PMID 9367129.
- ^ a b Huelsenbeck JP, Bollback JP (June 2001). "Empirical and hierarchical Bayesian estimation of ancestral states". Systematic Biology. 50 (3): 351–366. CiteSeerX 10.1.1.319.4271. doi:10.1080/106351501300317978. PMID 12116580.
- ^ Lutzoni F, Pagel M, Reeb V (June 2001). "Major fungal lineages are derived from lichen symbiotic ancestors". Nature. 411 (6840): 937–940. Bibcode:2001Natur.411..937L. doi:10.1038/35082053. PMID 11418855. S2CID 4414913.
- ^ Hanson-Smith V, Kolaczkowski B, Thornton JW (September 2010). "Robustness of ancestral sequence reconstruction to phylogenetic uncertainty". Molecular Biology and Evolution. 27 (9): 1988–1999. doi:10.1093/molbev/msq081. PMC 2922618. PMID 20368266.
- ^ Hillis DM, Bull JJ, White ME, Badgett MR, Molineux IJ (January 1992). "Experimental phylogenetics: generation of a known phylogeny". Science. 255 (5044): 589–592. Bibcode:1992Sci...255..589H. doi:10.1126/science.1736360. PMID 1736360.
- ^ Oakley TH, Cunningham CW (April 2000). "Independent contrasts succeed where ancestor reconstruction fails in a known bacteriophage phylogeny". Evolution; International Journal of Organic Evolution. 54 (2): 397–405. doi:10.1554/0014-3820(2000)054[0397:ICSWAR]2.0.CO;2. PMID 10937216. S2CID 198153271.
- ^ Finarelli JA, Flynn JJ (April 2006). "Ancestral state reconstruction of body size in the Caniformia (Carnivora, Mammalia): the effects of incorporating data from the fossil record". Systematic Biology. 55 (2): 301–313. doi:10.1080/10635150500541698. PMID 16611601.
- ^ Albert JS, Johnson DM, Knouft JH (2009). "Fossils provide better estimates of ancestral body size than do extant taxa in fishes". Acta Zoologica. 90: 357–384. doi:10.1111/j.1463-6395.2008.00364.x. ISSN 0001-7272.
- ^ Slater GJ, Harmon LJ, Alfaro ME (December 2012). "Integrating fossils with molecular phylogenies improves inference of trait evolution". Evolution; International Journal of Organic Evolution. 66 (12): 3931–3944. doi:10.1111/j.1558-5646.2012.01723.x. PMID 23206147. S2CID 24390146.
- ^ Webster AJ, Purvis A (January 2002). "Testing the accuracy of methods for reconstructing ancestral states of continuous characters". Proceedings. Biological Sciences. 269 (1487): 143–149. doi:10.1098/rspb.2001.1873. PMC 1690869. PMID 11798429.
- ^ Maddison WP, Midford PE, Otto SP (October 2007). "Estimating a binary character's effect on speciation and extinction". Systematic Biology. 56 (5): 701–710. CiteSeerX 10.1.1.150.2224. doi:10.1080/10635150701607033. PMID 17849325.
- ^ a b Martins EP (1994). "'Estimating the rate of phenotypic evolution from comparative data". American Naturalist. 144 (2): 193–209. doi:10.1086/285670. S2CID 85300707.
- ^ Felsenstein J (1988). "Phylogenies and quantitative characters". Annual Review of Ecology and Systematics. 19: 445–471. doi:10.1146/annurev.ecolsys.19.1.445.
- ^ Garland Jr T, Dickerman AW, Janis CM, Jones JA (1993). "Phylogenetic analysis of covariance by computer simulation". Systematic Biology. 42 (3): 265–292. doi:10.1093/sysbio/42.3.265.
- ^ Cooper, N., G. H. Thomas, C. Venditti, A. Meade, and R. P. Freckleton. 2015. A cautionary note on the use of Ornstein Uhlenbeck models in macroevolutionary studies. Biological Journal of the Linnean Society.
- ^ a b c d Elliot MG, Mooers AØ (November 2014). "Inferring ancestral states without assuming neutrality or gradualism using a stable model of continuous character evolution". BMC Evolutionary Biology. 14 (1): 226. arXiv:1302.5104. Bibcode:2014BMCEE..14..226E. doi:10.1186/s12862-014-0226-8. PMC 4266906. PMID 25427971.
- ^ Griffith OW, Blackburn DG, Brandley MC, Van Dyke JU, Whittington CM, Thompson MB (September 2015). "Ancestral state reconstructions require biological evidence to test evolutionary hypotheses: A case study examining the evolution of reproductive mode in squamate reptiles". Journal of Experimental Zoology. Part B, Molecular and Developmental Evolution. 324 (6): 493–503. Bibcode:2015JEZB..324..493G. doi:10.1002/jez.b.22614. PMID 25732809.
- ^ Erkenbrack EM, Ako-Asare K, Miller E, Tekelenburg S, Thompson JR, Romano L (January 2016). "Ancestral state reconstruction by comparative analysis of a GRN kernel operating in echinoderms". Development Genes and Evolution. 226 (1): 37–45. doi:10.1007/s00427-015-0527-y. PMID 26781941. S2CID 6067524.
- ^ Erkenbrack EM, Thompson JR (2019). "Cell type phylogenetics informs the evolutionary origin of echinoderm larval skeletogenic cell identity". Communications Biology. 2: 160. doi:10.1038/s42003-019-0417-3. PMC 6499829. PMID 31069269.
- ^ a b Chang BS, Ugalde JA, Matz MV (2005). "Applications of ancestral protein reconstruction in understanding protein function: GFP-like proteins". Molecular Evolution: Producing the Biochemical Data. Methods in Enzymology. Vol. 395. pp. 652–670. doi:10.1016/S0076-6879(05)95034-9. ISBN 9780121828004. PMID 15865989.
- ^ Hodges WL (November 2004). "Evolution of viviparity in horned lizards (Phrynosoma): testing the cold-climate hypothesis". Journal of Evolutionary Biology. 17 (6): 1230–1237. doi:10.1111/j.1420-9101.2004.00770.x. PMID 15525408. S2CID 25069395.
- ^ Maddison WP (1991). "Squared-change parsimony reconstructions of ancestral states for continuous-valued characters on a phylogenetic tree". Systematic Biology. 40 (3): 304–314. doi:10.1093/sysbio/40.3.304.
- ^ Bonine KE, Gleeson TT, Garland T (December 2005). "Muscle fiber-type variation in lizards (Squamata) and phylogenetic reconstruction of hypothesized ancestral states". The Journal of Experimental Biology. 208 (Pt 23): 4529–4547. doi:10.1242/jeb.01903. PMID 16339872.
- ^ Ridley M (1983). The explanation of organic diversity: the comparative method and adaptations for mating. Oxford: Clarendon Press.
- ^ Maddison WP (May 1990). "A Method for Testing the Correlated Evolution of Two Binary Characters: Are Gains or Losses Concentrated on Certain Branches of a Phylogenetic Tree?". Evolution; International Journal of Organic Evolution. 44 (3): 539–557. doi:10.2307/2409434. JSTOR 2409434. PMID 28567979.
- ^ Göbel U, Sander C, Schneider R, Valencia A (April 1994). "Correlated mutations and residue contacts in proteins". Proteins. 18 (4): 309–317. doi:10.1002/prot.340180402. PMID 8208723. S2CID 14978727.
- ^ Shindyalov IN, Kolchanov NA, Sander C (March 1994). "Can three-dimensional contacts in protein structures be predicted by analysis of correlated mutations?". Protein Engineering. 7 (3): 349–358. doi:10.1093/protein/7.3.349. PMID 8177884.
- ^ Korber BT, Farber RM, Wolpert DH, Lapedes AS (August 1993). "Covariation of mutations in the V3 loop of human immunodeficiency virus type 1 envelope protein: an information theoretic analysis". Proceedings of the National Academy of Sciences of the United States of America. 90 (15): 7176–7180. Bibcode:1993PNAS...90.7176K. doi:10.1073/pnas.90.15.7176. PMC 47099. PMID 8346232.
- ^ Shapiro B, Rambaut A, Pybus OG, Holmes EC (September 2006). "A phylogenetic method for detecting positive epistasis in gene sequences and its application to RNA virus evolution" (PDF). Molecular Biology and Evolution. 23 (9): 1724–1730. doi:10.1093/molbev/msl037. PMID 16774976.
- ^ Poon AF, Lewis FI, Pond SL, Frost SD (November 2007). "An evolutionary-network model reveals stratified interactions in the V3 loop of the HIV-1 envelope". PLOS Computational Biology. 3 (11): e231. Bibcode:2007PLSCB...3..231P. doi:10.1371/journal.pcbi.0030231. PMC 2082504. PMID 18039027.
- ^ Jermann TM, Opitz JG, Stackhouse J, Benner SA (March 1995). "Reconstructing the evolutionary history of the artiodactyl ribonuclease superfamily". Nature. 374 (6517): 57–59. Bibcode:1995Natur.374...57J. doi:10.1038/374057a0. PMID 7532788. S2CID 4315312.
- ^ Sadqi M, de Alba E, Pérez-Jiménez R, Sanchez-Ruiz JM, Muñoz V (March 2009). "A designed protein as experimental model of primordial folding". Proceedings of the National Academy of Sciences of the United States of America. 106 (11): 4127–4132. Bibcode:2009PNAS..106.4127S. doi:10.1073/pnas.0812108106. PMC 2647338. PMID 19240216.
- ^ Chang BS, Jönsson K, Kazmi MA, Donoghue MJ, Sakmar TP (September 2002). "Recreating a functional ancestral archosaur visual pigment". Molecular Biology and Evolution. 19 (9): 1483–1489. doi:10.1093/oxfordjournals.molbev.a004211. PMID 12200476.
- ^ Zhang C, Zhang M, Ju J, Nietfeldt J, Wise J, Terry PM, et al. (September 2003). "Genome diversification in phylogenetic lineages I and II of Listeria monocytogenes: identification of segments unique to lineage II populations". Journal of Bacteriology. 185 (18): 5573–5584. doi:10.1128/JB.185.18.5573-5584.2003. PMC 193770. PMID 12949110.
- ^ Krishnan NM, Seligmann H, Stewart CB, De Koning AP, Pollock DD (October 2004). "Ancestral sequence reconstruction in primate mitochondrial DNA: compositional bias and effect on functional inference". Molecular Biology and Evolution. 21 (10): 1871–1883. doi:10.1093/molbev/msh198. PMID 15229290.
- ^ Gaschen B, Taylor J, Yusim K, Foley B, Gao F, Lang D, et al. (June 2002). "Diversity considerations in HIV-1 vaccine selection". Science. 296 (5577): 2354–2360. Bibcode:2002Sci...296.2354G. doi:10.1126/science.1070441. PMID 12089434. S2CID 39452987.
- ^ Rolland M, Jensen MA, Nickle DC, Yan J, Learn GH, Heath L, et al. (August 2007). "Reconstruction and function of ancestral center-of-tree human immunodeficiency virus type 1 proteins". Journal of Virology. 81 (16): 8507–8514. doi:10.1128/JVI.02683-06. PMC 1951385. PMID 17537854.
- ^ Kothe DL, Li Y, Decker JM, Bibollet-Ruche F, Zammit KP, Salazar MG, et al. (September 2006). "Ancestral and consensus envelope immunogens for HIV-1 subtype C". Virology. 352 (2): 438–449. doi:10.1016/j.virol.2006.05.011. PMID 16780913.
- ^ Doria-Rose NA, Learn GH, Rodrigo AG, Nickle DC, Li F, Mahalanabis M, et al. (September 2005). "Human immunodeficiency virus type 1 subtype B ancestral envelope protein is functional and elicits neutralizing antibodies in rabbits similar to those elicited by a circulating subtype B envelope". Journal of Virology. 79 (17): 11214–11224. doi:10.1128/JVI.79.17.11214-11224.2005. PMC 1193599. PMID 16103173.
- ^ McCloskey RM, Liang RH, Harrigan PR, Brumme ZL, Poon AF (June 2014). "An evaluation of phylogenetic methods for reconstructing transmitted HIV variants using longitudinal clonal HIV sequence data". Journal of Virology. 88 (11): 6181–6194. doi:10.1128/JVI.00483-14. PMC 4093844. PMID 24648453.
- ^ Bourque G, Pevzner PA (January 2002). "Genome-scale evolution: reconstructing gene orders in the ancestral species". Genome Research. 12 (1): 26–36. PMC 155248. PMID 11779828.
- ^ Even S, Goldreich O (1981). "The minimum-length generator sequence problem is NP-hard". Journal of Algorithms. 2 (3): 311–313. doi:10.1016/0196-6774(81)90029-8. ISSN 0196-6774.
- ^ Fertin G, Labarre A, Rusu I, Vialette S, Tannier E (2009). Combinatorics of Genome Rearrangements. MIT Press. doi:10.7551/mitpress/9780262062824.001.0001. ISBN 9780262258753.
- ^ Wienberg J (December 2004). "The evolution of eutherian chromosomes". Current Opinion in Genetics & Development. 14 (6): 657–666. doi:10.1016/j.gde.2004.10.001. PMID 15531161.
- ^ Froenicke L, Caldés MG, Graphodatsky A, Müller S, Lyons LA, Robinson TJ, et al. (March 2006). "Are molecular cytogenetics and bioinformatics suggesting diverging models of ancestral mammalian genomes?". Genome Research. 16 (3): 306–310. doi:10.1101/gr.3955206. PMC 1415215. PMID 16510895.
- ^ Murphy WJ, Larkin DM, Everts-van der Wind A, Bourque G, Tesler G, Auvil L, et al. (July 2005). "Dynamics of mammalian chromosome evolution inferred from multispecies comparative maps". Science. 309 (5734): 613–617. Bibcode:2005Sci...309..613M. doi:10.1126/science.1111387. PMID 16040707. S2CID 32314883.
- ^ Ma J, Zhang L, Suh BB, Raney BJ, Burhans RC, Kent WJ, et al. (December 2006). "Reconstructing contiguous regions of an ancestral genome". Genome Research. 16 (12): 1557–1565. doi:10.1101/gr.5383506. PMC 1665639. PMID 16983148.
- ^ Oyserman BO, Moya F, Lawson CE, Garcia AL, Vogt M, Heffernen M, et al. (December 2016). "Ancestral genome reconstruction identifies the evolutionary basis for trait acquisition in polyphosphate accumulating bacteria". The ISME Journal. 10 (12): 2931–2945. Bibcode:2016ISMEJ..10.2931O. doi:10.1038/ismej.2016.67. PMC 5148189. PMID 27128993.
- ^ a b c Clark JR, Ree RH, Alfaro ME, King MG, Wagner WL, Roalson EH (October 2008). "A comparative study in ancestral range reconstruction methods: retracing the uncertain histories of insular lineages". Systematic Biology. 57 (5): 693–707. doi:10.1080/10635150802426473. PMID 18853357.
- ^ Huelsenbeck JP, Nielsen R, Bollback JP (April 2003). "Stochastic mapping of morphological characters". Systematic Biology. 52 (2): 131–158. CiteSeerX 10.1.1.386.9241. doi:10.1080/10635150390192780. PMID 12746144.
- ^ Ronquist F (1996). "DIVA version 1.1".
Computer program and manual available by anonymous FTP from Uppsala University
[permanent dead link] - ^ Ree RH, Moore BR, Webb CO, Donoghue MJ (November 2005). "A likelihood framework for inferring the evolution of geographic range on phylogenetic trees". Evolution; International Journal of Organic Evolution. 59 (11): 2299–2311. doi:10.1111/j.0014-3820.2005.tb00940.x. PMID 16396171. S2CID 23245573.
- ^ a b c Lemmon AR, Lemmon EM (August 2008). "A likelihood framework for estimating phylogeographic history on a continuous landscape". Systematic Biology. 57 (4): 544–561. CiteSeerX 10.1.1.585.7211. doi:10.1080/10635150802304761. PMID 18686193.
- ^ a b Sturtevant AH, Dobzhansky T (July 1936). "Inversions in the Third Chromosome of Wild Races of Drosophila Pseudoobscura, and Their Use in the Study of the History of the Species". Proceedings of the National Academy of Sciences of the United States of America. 22 (7): 448–450. Bibcode:1936PNAS...22..448S. doi:10.1073/pnas.22.7.448. PMC 1076803. PMID 16577723.
- ^ a b Campbell L (1998). Historical linguistics: an introduction. Edinburgh: Edinburgh University Press.
- ^ Yang Z (August 2007). "PAML 4: phylogenetic analysis by maximum likelihood". Molecular Biology and Evolution. 24 (8): 1586–1591. CiteSeerX 10.1.1.322.1650. doi:10.1093/molbev/msm088. PMID 17483113.
- ^ "Lazarus: a software tool for reconstructing ancestral protein sequences". markov.uoregon.edu. Archived from the original on 2015-03-07. Retrieved 2019-03-07.
- ^ Pond SL, Frost SD, Muse SV (March 2005). "HyPhy: hypothesis testing using phylogenies". Bioinformatics. 21 (5): 676–679. doi:10.1093/bioinformatics/bti079. PMID 15509596.
- ^ Maddison WP, Maddison DR (2015). "Mesquite: a modular system for evolutionary analysis. Version 2.75".
- ^ a b Tamura K, Stecher G, Peterson D, Filipski A, Kumar S (December 2013). "MEGA6: Molecular Evolutionary Genetics Analysis version 6.0". Molecular Biology and Evolution. 30 (12): 2725–2729. doi:10.1093/molbev/mst197. PMC 3840312. PMID 24132122.
- ^ Ronquist F, Huelsenbeck JP (August 2003). "MrBayes 3: Bayesian phylogenetic inference under mixed models". Bioinformatics. 19 (12): 1572–1574. doi:10.1093/bioinformatics/btg180. PMID 12912839.
- ^ Hubisz MJ, Pollard KS, Siepel A (January 2011). "PHAST and RPHAST: phylogenetic analysis with space/time models". Briefings in Bioinformatics. 12 (1): 41–51. doi:10.1093/bib/bbq072. PMC 3030812. PMID 21278375.
- ^ Bollback JP (February 2006). "SIMMAP: stochastic character mapping of discrete traits on phylogenies". BMC Bioinformatics. 7 (1): 88. doi:10.1186/1471-2105-7-88. PMC 1403802. PMID 16504105.
- ^ Paradis E (2012). Analysis of Phylogenetics and Evolution with R. New York: Springer-Verlag.
- ^ Rossnes R, Eidhammer I, Liberles DA (May 2005). "Phylogenetic reconstruction of ancestral character states for gene expression and mRNA splicing data". BMC Bioinformatics. 6 (1): 127. doi:10.1186/1471-2105-6-127. PMC 1166541. PMID 15921519.
- ^ Drummond AJ, Suchard MA, Xie D, Rambaut A (August 2012). "Bayesian phylogenetics with BEAUti and the BEAST 1.7". Molecular Biology and Evolution. 29 (8): 1969–1973. doi:10.1093/molbev/mss075. PMC 3408070. PMID 22367748.
- ^ FitzJohn RG (2012). "Diversitree: comparative phylogenetic analyses of diversification in R". Methods in Ecology and Evolution. 3 (6): 1084–1092. Bibcode:2012MEcEv...3.1084F. doi:10.1111/j.2041-210X.2012.00234.x. ISSN 2041-210X. S2CID 82351808.
- ^ Pagel M (1994). "Detecting Correlated Evolution on Phylogenies: A General Method for the Comparative Analysis of Discrete Characters". Proceedings of the Royal Society B: Biological Sciences. 255 (1342): 37–45. Bibcode:1994RSPSB.255...37P. doi:10.1098/rspb.1994.0006. ISSN 0962-8452. S2CID 85903564.
- ^ Yu Y, Harris AJ, He X (August 2010). "S-DIVA (Statistical Dispersal-Vicariance Analysis): A tool for inferring biogeographic histories". Molecular Phylogenetics and Evolution. 56 (2): 848–850. Bibcode:2010MolPE..56..848Y. doi:10.1016/j.ympev.2010.04.011. PMID 20399277. S2CID 44980641.
- ^ Arias JS, Szumik CA, Goloboff PA (December 2011). "Spatial analysis of vicariance: a method for using direct geographical information in historical biogeography". Cladistics. 27 (6): 617–628. doi:10.1111/j.1096-0031.2011.00353.x. hdl:11336/70196. PMID 34875812. S2CID 85747431.
- ^ Jones BR, Rajaraman A, Tannier E, Chauve C (September 2012). "ANGES: reconstructing ANcestral GEnomeS maps". Bioinformatics. 28 (18): 2388–2390. doi:10.1093/bioinformatics/bts457. PMID 22820205.
- ^ Larget B, Kadane JB, Simon DL (August 2005). "A Bayesian approach to the estimation of ancestral genome arrangements". Molecular Phylogenetics and Evolution. 36 (2): 214–223. Bibcode:2005MolPE..36..214L. doi:10.1016/j.ympev.2005.03.026. PMID 15893477.
- ^ Csurös M (August 2010). "Count: evolutionary analysis of phylogenetic profiles with parsimony and likelihood". Bioinformatics. 26 (15): 1910–1912. doi:10.1093/bioinformatics/btq315. PMID 20551134.
- ^ Carmel L, Wolf YI, Rogozin IB, Koonin EV (2010). "EREM: Parameter Estimation and Ancestral Reconstruction by Expectation-Maximization Algorithm for a Probabilistic Model of Genomic Binary Characters Evolution". Advances in Bioinformatics. 2010: 167408. doi:10.1155/2010/167408. PMC 2866244. PMID 20467467.
- ^ Patro R, Sefer E, Malin J, Marçais G, Navlakha S, Kingsford C (September 2012). "Parsimonious reconstruction of network evolution". Algorithms for Molecular Biology. 7 (1): 25. doi:10.1186/1748-7188-7-25. PMC 3492119. PMID 22992218.
- ^ Diallo AB, Makarenkov V, Blanchette M (January 2010). "Ancestors 1.0: a web server for ancestral sequence reconstruction". Bioinformatics. 26 (1): 130–131. doi:10.1093/bioinformatics/btp600. PMID 19850756.
- ^ Ashkenazy H, Penn O, Doron-Faigenboim A, Cohen O, Cannarozzi G, Zomer O, Pupko T (July 2012). "FastML: a web server for probabilistic reconstruction of ancestral sequences". Nucleic Acids Research. 40 (Web Server issue): W580–W584. doi:10.1093/nar/gks498. PMC 3394241. PMID 22661579.
- ^ Hu F, Lin Y, Tang J (November 2014). "MLGO: phylogeny reconstruction and ancestral inference from gene-order data". BMC Bioinformatics. 15 (1): 354. doi:10.1186/s12859-014-0354-6. PMC 4236499. PMID 25376663.
- ^ Bouchard-Côté A, Jordan MI (January 2013). "Evolutionary inference via the Poisson Indel Process". Proceedings of the National Academy of Sciences of the United States of America. 110 (4): 1160–1166. arXiv:1207.6327. Bibcode:2013PNAS..110.1160B. doi:10.1073/pnas.1220450110. PMC 3557041. PMID 23275296.
- ^ Thorne JL, Kishino H, Felsenstein J (August 1991). "An evolutionary model for maximum likelihood alignment of DNA sequences". Journal of Molecular Evolution. 33 (2): 114–124. Bibcode:1991JMolE..33..114T. doi:10.1007/BF02193625. PMID 1920447. S2CID 13333056.
- ^ Poon AF, Swenson LC, Bunnik EM, Edo-Matas D, Schuitemaker H, van 't Wout AB, Harrigan PR (2012). "Reconstructing the dynamics of HIV evolution within hosts from serial deep sequence data". PLOS Computational Biology. 8 (11): e1002753. Bibcode:2012PLSCB...8E2753P. doi:10.1371/journal.pcbi.1002753. PMC 3486858. PMID 23133358.
- ^ Schwarz RF, Trinh A, Sipos B, Brenton JD, Goldman N, Markowetz F (April 2014). "Phylogenetic quantification of intra-tumour heterogeneity". PLOS Computational Biology. 10 (4): e1003535. arXiv:1306.1685. Bibcode:2014PLSCB..10E3535S. doi:10.1371/journal.pcbi.1003535. PMC 3990475. PMID 24743184.