This article needs additional citations for verification. (January 2023) |
Spatial analysis is any of the formal techniques which studies entities using their topological, geometric, or geographic properties. Spatial analysis includes a variety of techniques using different analytic approaches, especially spatial statistics. It may be applied in fields as diverse as astronomy, with its studies of the placement of galaxies in the cosmos, or to chip fabrication engineering, with its use of "place and route" algorithms to build complex wiring structures. In a more restricted sense, spatial analysis is geospatial analysis, the technique applied to structures at the human scale, most notably in the analysis of geographic data. It may also be applied to genomics, as in transcriptomics data.

Complex issues arise in spatial analysis, many of which are neither clearly defined nor completely resolved, but form the basis for current research. The most fundamental of these is the problem of defining the spatial location of the entities being studied. Classification of the techniques of spatial analysis is difficult because of the large number of different fields of research involved, the different fundamental approaches which can be chosen, and the many forms the data can take.
History
editSpatial analysis began with early attempts at cartography and surveying. Land surveying goes back to at least 1,400 B.C in Egypt: the dimensions of taxable land plots were measured with measuring ropes and plumb bobs.[1] Many fields have contributed to its rise in modern form. Biology contributed through botanical studies of global plant distributions and local plant locations, ethological studies of animal movement, landscape ecological studies of vegetation blocks, ecological studies of spatial population dynamics, and the study of biogeography. Epidemiology contributed with early work on disease mapping, notably John Snow's work of mapping an outbreak of cholera, with research on mapping the spread of disease and with location studies for health care delivery. Statistics has contributed greatly through work in spatial statistics. Economics has contributed notably through spatial econometrics. Geographic information system is currently a major contributor due to the importance of geographic software in the modern analytic toolbox. Remote sensing has contributed extensively in morphometric and clustering analysis. Computer science has contributed extensively through the study of algorithms, notably in computational geometry. Mathematics continues to provide the fundamental tools for analysis and to reveal the complexity of the spatial realm, for example, with recent work on fractals and scale invariance. Scientific modelling provides a useful framework for new approaches.[citation needed]
Fundamental issues
editSpatial analysis confronts many fundamental issues in the definition of its objects of study, in the construction of the analytic operations to be used, in the use of computers for analysis, in the limitations and particularities of the analyses which are known, and in the presentation of analytic results. Many of these issues are active subjects of modern research.[citation needed]
Common errors often arise in spatial analysis, some due to the mathematics of space, some due to the particular ways data are presented spatially, some due to the tools which are available. Census data, because it protects individual privacy by aggregating data into local units, raises a number of statistical issues. The fractal nature of coastline makes precise measurements of its length difficult if not impossible. A computer software fitting straight lines to the curve of a coastline, can easily calculate the lengths of the lines which it defines. However these straight lines may have no inherent meaning in the real world, as was shown for the coastline of Britain.[citation needed]
These problems represent a challenge in spatial analysis because of the power of maps as media of presentation. When results are presented as maps, the presentation combines spatial data which are generally accurate with analytic results which may be inaccurate, leading to an impression that analytic results are more accurate than the data would indicate.[2]
Formal Problems
editBoundary problem
editModifiable areal unit problem
edit
The modifiable areal unit problem (MAUP) is a source of statistical bias that can significantly impact the results of statistical hypothesis tests. MAUP affects results when point-based measures of spatial phenomena are aggregated into spatial partitions or areal units (such as regions or districts) as in, for example, population density or illness rates.[3][4] The resulting summary values (e.g., totals, rates, proportions, densities) are influenced by both the shape and scale of the aggregation unit.[5]
For example, census data may be aggregated into county districts, census tracts, postcode areas, police precincts, or any other arbitrary spatial partition. Thus the results of data aggregation are dependent on the mapmaker's choice of which "modifiable areal unit" to use in their analysis. A census choropleth map calculating population density using state boundaries will yield radically different results than a map that calculates density based on county boundaries. Furthermore, census district boundaries are also subject to change over time,[6] meaning the MAUP must be considered when comparing past data to current data.Modifiable temporal unit problem
edit
Neighborhood effect averaging problem
editTravelling salesman problem
edit
In the theory of computational complexity, the travelling salesman problem (TSP) asks the following question: "Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?" It is an NP-hard problem in combinatorial optimization, important in theoretical computer science and operations research.
The travelling purchaser problem, the vehicle routing problem and the ring star problem[15] are three generalizations of TSP.
The decision version of the TSP (where given a length L, the task is to decide whether the graph has a tour whose length is at most L) belongs to the class of NP-complete problems. Thus, it is possible that the worst-case running time for any algorithm for the TSP increases superpolynomially (but no more than exponentially) with the number of cities.
The problem was first formulated in 1930 and is one of the most intensively studied problems in optimization. It is used as a benchmark for many optimization methods. Even though the problem is computationally difficult, many heuristics and exact algorithms are known, so that some instances with tens of thousands of cities can be solved completely, and even problems with millions of cities can be approximated within a small fraction of 1%.[16]Uncertain geographic context problem
edit
Weber problem
editIn geometry, the Weber problem, named after Alfred Weber, is one of the most famous problems in location theory. It requires finding a point in the plane that minimizes the sum of the transportation costs from this point to n destination points, where different destination points are associated with different costs per unit distance.
The Weber problem generalizes the geometric median, which assumes transportation costs per unit distance are the same for all destination points, and the problem of computing the Fermat point, the geometric median of three points. For this reason it is sometimes called the Fermat–Weber problem, although the same name has also been used for the unweighted geometric median problem. The Weber problem is in turn generalized by the attraction–repulsion problem, which allows some of the costs to be negative, so that greater distance from some points is better.Spatial characterization
edit
The definition of the spatial presence of an entity constrains the possible analysis which can be applied to that entity and influences the final conclusions that can be reached. While this property is fundamentally true of all analysis, it is particularly important in spatial analysis because the tools to define and study entities favor specific characterizations of the entities being studied. Statistical techniques favor the spatial definition of objects as points because there are very few statistical techniques which operate directly on line, area, or volume elements. Computer tools favor the spatial definition of objects as homogeneous and separate elements because of the limited number of database elements and computational structures available, and the ease with which these primitive structures can be created.[citation needed]
Spatial dependence
editSpatial dependence is the spatial relationship of variable values (for themes defined over space, such as rainfall) or locations (for themes defined as objects, such as cities). Spatial dependence is measured as the existence of statistical dependence in a collection of random variables, each of which is associated with a different geographical location. Spatial dependence is of importance in applications where it is reasonable to postulate the existence of corresponding set of random variables at locations that have not been included in a sample. Thus rainfall may be measured at a set of rain gauge locations, and such measurements can be considered as outcomes of random variables, but rainfall clearly occurs at other locations and would again be random. Because rainfall exhibits properties of autocorrelation, spatial interpolation techniques can be used to estimate rainfall amounts at locations near measured locations.[32]
As with other types of statistical dependence, the presence of spatial dependence generally leads to estimates of an average value from a sample being less accurate than had the samples been independent, although if negative dependence exists a sample average can be better than in the independent case. A different problem than that of estimating an overall average is that of spatial interpolation: here the problem is to estimate the unobserved random outcomes of variables at locations intermediate to places where measurements are made, on that there is spatial dependence between the observed and unobserved random variables.[citation needed]
Tools for exploring spatial dependence include: spatial correlation, spatial covariance functions and semivariograms. Methods for spatial interpolation include Kriging, which is a type of best linear unbiased prediction. The topic of spatial dependence is of importance to geostatistics and spatial analysis.[citation needed]
Spatial auto-correlation
editSpatial dependency is the co-variation of properties within geographic space: characteristics at proximal locations appear to be correlated, either positively or negatively.[33] Spatial dependency leads to the spatial autocorrelation problem in statistics since, like temporal autocorrelation, this violates standard statistical techniques that assume independence among observations. For example, regression analyses that do not compensate for spatial dependency can have unstable parameter estimates and yield unreliable significance tests. Spatial regression models (see below) capture these relationships and do not suffer from these weaknesses. It is also appropriate to view spatial dependency as a source of information rather than something to be corrected.[34]
Locational effects also manifest as spatial heterogeneity, or the apparent variation in a process with respect to location in geographic space. Unless a space is uniform and boundless, every location will have some degree of uniqueness relative to the other locations. This affects the spatial dependency relations and therefore the spatial process. Spatial heterogeneity means that overall parameters estimated for the entire system may not adequately describe the process at any given location.[citation needed]
Spatial association
editSpatial association is the degree to which things are similarly arranged in space. Analysis of the distribution patterns of two phenomena is done by map overlay. If the distributions are similar, then the spatial association is strong, and vice versa.[35] In a Geographic Information System, the analysis can be done quantitatively. For example, a set of observations (as points or extracted from raster cells) at matching locations can be intersected and examined by regression analysis.
Like spatial autocorrelation, this can be a useful tool for spatial prediction. In spatial modeling, the concept of spatial association allows the use of covariates in a regression equation to predict the geographic field and thus produce a map.
The second dimension of spatial association
editThe second dimension of spatial association (SDA) reveals the association between spatial variables through extracting geographical information at locations outside samples. SDA effectively uses the missing geographical information outside sample locations in methods of the first dimension of spatial association (FDA), which explore spatial association using observations at sample locations.[36]
Scaling
editSpatial measurement scale is a persistent issue in spatial analysis; more detail is available at the modifiable areal unit problem (MAUP) topic entry. Landscape ecologists developed a series of scale invariant metrics for aspects of ecology that are fractal in nature.[37] In more general terms, no scale independent method of analysis is widely agreed upon for spatial statistics.[citation needed]
Sampling
editSpatial sampling involves determining a limited number of locations in geographic space for faithfully measuring phenomena that are subject to dependency and heterogeneity. [citation needed] Dependency suggests that since one location can predict the value of another location, we do not need observations in both places. But heterogeneity suggests that this relation can change across space, and therefore we cannot trust an observed degree of dependency beyond a region that may be small. Basic spatial sampling schemes include random, clustered and systematic. These basic schemes can be applied at multiple levels in a designated spatial hierarchy (e.g., urban area, city, neighborhood). It is also possible to exploit ancillary data, for example, using property values as a guide in a spatial sampling scheme to measure educational attainment and income. Spatial models such as autocorrelation statistics, regression and interpolation (see below) can also dictate sample design.[citation needed]
Common errors in spatial analysis
editThe fundamental issues in spatial analysis lead to numerous problems in analysis including bias, distortion and outright errors in the conclusions reached. These issues are often interlinked but various attempts have been made to separate out particular issues from each other.[38]
Length
editIn discussing the coastline of Britain, Benoit Mandelbrot showed that certain spatial concepts are inherently nonsensical despite presumption of their validity. Lengths in ecology depend directly on the scale at which they are measured and experienced. So while surveyors commonly measure the length of a river, this length only has meaning in the context of the relevance of the measuring technique to the question under study.[39]
-
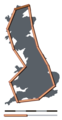 Britain measured using a 200 km linear measurement
Britain measured using a 200 km linear measurement -
 Britain measured using a 100 km linear measurement
Britain measured using a 100 km linear measurement -
 Britain measured using a 50 km linear measurement
Britain measured using a 50 km linear measurement



Locational fallacy
editThe locational fallacy refers to error due to the particular spatial characterization chosen for the elements of study, in particular choice of placement for the spatial presence of the element.[39]
Spatial characterizations may be simplistic or even wrong. Studies of humans often reduce the spatial existence of humans to a single point, for instance their home address. This can easily lead to poor analysis, for example, when considering disease transmission which can happen at work or at school and therefore far from the home.[39]
The spatial characterization may implicitly limit the subject of study. For example, the spatial analysis of crime data has recently become popular but these studies can only describe the particular kinds of crime which can be described spatially. This leads to many maps of assault but not to any maps of embezzlement with political consequences in the conceptualization of crime and the design of policies to address the issue.[39]
Atomic fallacy
editThis describes errors due to treating elements as separate 'atoms' outside of their spatial context.[39] The fallacy is about transferring individual conclusions to spatial units.[40]
Ecological fallacy
editThe ecological fallacy describes errors due to performing analyses on aggregate data when trying to reach conclusions on the individual units.[39][41] Errors occur in part from spatial aggregation. For example, a pixel represents the average surface temperatures within an area. Ecological fallacy would be to assume that all points within the area have the same temperature.
Solutions to the fundamental issues
editGeographic space
edit
A mathematical space exists whenever we have a set of observations and quantitative measures of their attributes. For example, we can represent individuals' incomes or years of education within a coordinate system where the location of each individual can be specified with respect to both dimensions. The distance between individuals within this space is a quantitative measure of their differences with respect to income and education. However, in spatial analysis, we are concerned with specific types of mathematical spaces, namely, geographic space. In geographic space, the observations correspond to locations in a spatial measurement framework that capture their proximity in the real world. The locations in a spatial measurement framework often represent locations on the surface of the Earth, but this is not strictly necessary. A spatial measurement framework can also capture proximity with respect to, say, interstellar space or within a biological entity such as a liver. The fundamental tenet is Tobler's First Law of Geography: if the interrelation between entities increases with proximity in the real world, then representation in geographic space and assessment using spatial analysis techniques are appropriate.
The Euclidean distance between locations often represents their proximity, although this is only one possibility. There are an infinite number of distances in addition to Euclidean that can support quantitative analysis. For example, "Manhattan" (or "Taxicab") distances where movement is restricted to paths parallel to the axes can be more meaningful than Euclidean distances in urban settings. In addition to distances, other geographic relationships such as connectivity (e.g., the existence or degree of shared borders) and direction can also influence the relationships among entities. It is also possible to compute minimal cost paths across a cost surface; for example, this can represent proximity among locations when travel must occur across rugged terrain.
Types
editSpatial data comes in many varieties and it is not easy to arrive at a system of classification that is simultaneously exclusive, exhaustive, imaginative, and satisfying. -- G. Upton & B. Fingelton[42]
Spatial data analysis
editUrban and Regional Studies deal with large tables of spatial data obtained from censuses and surveys. It is necessary to simplify the huge amount of detailed information in order to extract the main trends. Multivariable analysis (or Factor analysis, FA) allows a change of variables, transforming the many variables of the census, usually correlated between themselves, into fewer independent "Factors" or "Principal Components" which are, actually, the eigenvectors of the data correlation matrix weighted by the inverse of their eigenvalues. This change of variables has two main advantages:
- Since information is concentrated on the first new factors, it is possible to keep only a few of them while losing only a small amount of information; mapping them produces fewer and more significant maps
- The factors, actually the eigenvectors, are orthogonal by construction, i.e. not correlated. In most cases, the dominant factor (with the largest eigenvalue) is the Social Component, separating rich and poor in the city. Since factors are not-correlated, other smaller processes than social status, which would have remained hidden otherwise, appear on the second, third, ... factors.
Factor analysis depends on measuring distances between observations : the choice of a significant metric is crucial. The Euclidean metric (Principal Component Analysis), the Chi-Square distance (Correspondence Analysis) or the Generalized Mahalanobis distance (Discriminant Analysis) are among the more widely used.[43] More complicated models, using communalities or rotations have been proposed.[44]
Using multivariate methods in spatial analysis began really in the 1950s (although some examples go back to the beginning of the century) and culminated in the 1970s, with the increasing power and accessibility of computers. Already in 1948, in a seminal publication, two sociologists, Wendell Bell and Eshref Shevky,[45] had shown that most city populations in the US and in the world could be represented with three independent factors : 1- the « socio-economic status » opposing rich and poor districts and distributed in sectors running along highways from the city center, 2- the « life cycle », i.e. the age structure of households, distributed in concentric circles, and 3- « race and ethnicity », identifying patches of migrants located within the city. In 1961, in a groundbreaking study, British geographers used FA to classify British towns.[46] Brian J Berry, at the University of Chicago, and his students made a wide use of the method,[47] applying it to most important cities in the world and exhibiting common social structures.[48] The use of Factor Analysis in Geography, made so easy by modern computers, has been very wide but not always very wise.[49]
Since the vectors extracted are determined by the data matrix, it is not possible to compare factors obtained from different censuses. A solution consists in fusing together several census matrices in a unique table which, then, may be analyzed. This, however, assumes that the definition of the variables has not changed over time and produces very large tables, difficult to manage. A better solution, proposed by psychometricians,[50] groups the data in a « cubic matrix », with three entries (for instance, locations, variables, time periods). A Three-Way Factor Analysis produces then three groups of factors related by a small cubic « core matrix ».[51] This method, which exhibits data evolution over time, has not been widely used in geography.[52] In Los Angeles,[53] however, it has exhibited the role, traditionally ignored, of Downtown as an organizing center for the whole city during several decades.
Spatial autocorrelation
editSpatial autocorrelation statistics measure and analyze the degree of dependency among observations in a geographic space. Classic spatial autocorrelation statistics include Moran's , Geary's , Getis's and the standard deviational ellipse. These statistics require measuring a spatial weights matrix that reflects the intensity of the geographic relationship between observations in a neighborhood, e.g., the distances between neighbors, the lengths of shared border, or whether they fall into a specified directional class such as "west". Classic spatial autocorrelation statistics compare the spatial weights to the covariance relationship at pairs of locations. Spatial autocorrelation that is more positive than expected from random indicate the clustering of similar values across geographic space, while significant negative spatial autocorrelation indicates that neighboring values are more dissimilar than expected by chance, suggesting a spatial pattern similar to a chess board.



Spatial autocorrelation statistics such as Moran's and Geary's are global in the sense that they estimate the overall degree of spatial autocorrelation for a dataset. The possibility of spatial heterogeneity suggests that the estimated degree of autocorrelation may vary significantly across geographic space. Local spatial autocorrelation statistics provide estimates disaggregated to the level of the spatial analysis units, allowing assessment of the dependency relationships across space. statistics compare neighborhoods to a global average and identify local regions of strong autocorrelation. Local versions of the and statistics are also available.
Spatial heterogeneity
edit
Spatial interaction
editSpatial interaction or "gravity models" estimate the flow of people, material or information between locations in geographic space. Factors can include origin propulsive variables such as the number of commuters in residential areas, destination attractiveness variables such as the amount of office space in employment areas, and proximity relationships between the locations measured in terms such as driving distance or travel time. In addition, the topological, or connective, relationships between areas must be identified, particularly considering the often conflicting relationship between distance and topology; for example, two spatially close neighborhoods may not display any significant interaction if they are separated by a highway. After specifying the functional forms of these relationships, the analyst can estimate model parameters using observed flow data and standard estimation techniques such as ordinary least squares or maximum likelihood. Competing destinations versions of spatial interaction models include the proximity among the destinations (or origins) in addition to the origin-destination proximity; this captures the effects of destination (origin) clustering on flows.
Spatial interpolation
editSpatial interpolation methods estimate the variables at unobserved locations in geographic space based on the values at observed locations. Basic methods include inverse distance weighting: this attenuates the variable with decreasing proximity from the observed location. Kriging is a more sophisticated method that interpolates across space according to a spatial lag relationship that has both systematic and random components. This can accommodate a wide range of spatial relationships for the hidden values between observed locations. Kriging provides optimal estimates given the hypothesized lag relationship, and error estimates can be mapped to determine if spatial patterns exist.
Spatial regression
editSpatial regression methods capture spatial dependency in regression analysis, avoiding statistical problems such as unstable parameters and unreliable significance tests, as well as providing information on spatial relationships among the variables involved. Depending on the specific technique, spatial dependency can enter the regression model as relationships between the independent variables and the dependent, between the dependent variables and a spatial lag of itself, or in the error terms. Geographically weighted regression (GWR) is a local version of spatial regression that generates parameters disaggregated by the spatial units of analysis.[54] This allows assessment of the spatial heterogeneity in the estimated relationships between the independent and dependent variables. The use of Bayesian hierarchical modeling[55] in conjunction with Markov chain Monte Carlo (MCMC) methods have recently shown to be effective in modeling complex relationships using Poisson-Gamma-CAR, Poisson-lognormal-SAR, or Overdispersed logit models. Statistical packages for implementing such Bayesian models using MCMC include WinBugs, CrimeStat and many packages available via R programming language.[56]
Spatial stochastic processes, such as Gaussian processes are also increasingly being deployed in spatial regression analysis. Model-based versions of GWR, known as spatially varying coefficient models have been applied to conduct Bayesian inference.[55] Spatial stochastic process can become computationally effective and scalable Gaussian process models, such as Gaussian Predictive Processes[57] and Nearest Neighbor Gaussian Processes (NNGP).[58]
Spatial neural networks
editSimulation and modeling
editSpatial interaction models are aggregate and top-down: they specify an overall governing relationship for flow between locations. This characteristic is also shared by urban models such as those based on mathematical programming, flows among economic sectors, or bid-rent theory. An alternative modeling perspective is to represent the system at the highest possible level of disaggregation and study the bottom-up emergence of complex patterns and relationships from behavior and interactions at the individual level. [citation needed]
Complex adaptive systems theory as applied to spatial analysis suggests that simple interactions among proximal entities can lead to intricate, persistent and functional spatial entities at aggregate levels. Two fundamentally spatial simulation methods are cellular automata and agent-based modeling. Cellular automata modeling imposes a fixed spatial framework such as grid cells and specifies rules that dictate the state of a cell based on the states of its neighboring cells. As time progresses, spatial patterns emerge as cells change states based on their neighbors; this alters the conditions for future time periods. For example, cells can represent locations in an urban area and their states can be different types of land use. Patterns that can emerge from the simple interactions of local land uses include office districts and urban sprawl. Agent-based modeling uses software entities (agents) that have purposeful behavior (goals) and can react, interact and modify their environment while seeking their objectives. Unlike the cells in cellular automata, simulysts can allow agents to be mobile with respect to space. For example, one could model traffic flow and dynamics using agents representing individual vehicles that try to minimize travel time between specified origins and destinations. While pursuing minimal travel times, the agents must avoid collisions with other vehicles also seeking to minimize their travel times. Cellular automata and agent-based modeling are complementary modeling strategies. They can be integrated into a common geographic automata system where some agents are fixed while others are mobile.
Calibration plays a pivotal role in both CA and ABM simulation and modelling approaches. Initial approaches to CA proposed robust calibration approaches based on stochastic, Monte Carlo methods.[62][63] ABM approaches rely on agents' decision rules (in many cases extracted from qualitative research base methods such as questionnaires).[64] Recent Machine Learning Algorithms calibrate using training sets, for instance in order to understand the qualities of the built environment.[65]
Multiple-point geostatistics (MPS)
editSpatial analysis of a conceptual geological model is the main purpose of any MPS algorithm. The method analyzes the spatial statistics of the geological model, called the training image, and generates realizations of the phenomena that honor those input multiple-point statistics.
A recent MPS algorithm used to accomplish this task is the pattern-based method by Honarkhah.[66] In this method, a distance-based approach is employed to analyze the patterns in the training image. This allows the reproduction of the multiple-point statistics, and the complex geometrical features of the training image. Each output of the MPS algorithm is a realization that represents a random field. Together, several realizations may be used to quantify spatial uncertainty.
One of the recent methods is presented by Tahmasebi et al.[67] uses a cross-correlation function to improve the spatial pattern reproduction. They call their MPS simulation method as the CCSIM algorithm. This method is able to quantify the spatial connectivity, variability and uncertainty. Furthermore, the method is not sensitive to any type of data and is able to simulate both categorical and continuous scenarios. CCSIM algorithm is able to be used for any stationary, non-stationary and multivariate systems and it can provide high quality visual appeal model.,[68][69]
Geospatial and hydrospatial analysis
editThis section may need to be cleaned up. It has been merged from Geospatial analysis. |
Geospatial and hydrospatial analysis, or just spatial analysis,[70] is an approach to applying statistical analysis and other analytic techniques to data which has a geographical or spatial aspect. Such analysis would typically employ software capable of rendering maps processing spatial data, and applying analytical methods to terrestrial or geographic datasets, including the use of geographic information systems and geomatics.[71][72][73]
Geographical information system usage
editGeographic information systems (GIS) — a large domain that provides a variety of capabilities designed to capture, store, manipulate, analyze, manage, and present all types of geographical data — utilizes geospatial and hydrospatial analysis in a variety of contexts, operations and applications.
Basic applications
editGeospatial and Hydrospatial analysis, using GIS, was developed for problems in the environmental and life sciences, in particular ecology, geology and epidemiology. It has extended to almost all industries including defense, intelligence, utilities, Natural Resources (i.e. Oil and Gas, Forestry ... etc.), social sciences, medicine and Public Safety (i.e. emergency management and criminology), disaster risk reduction and management (DRRM), and climate change adaptation (CCA). Spatial statistics typically result primarily from observation rather than experimentation. Hydrospatial is particularly used for the aquatic side and the members related to the water surface, column, bottom, sub-bottom and the coastal zones.
Basic operations
editVector-based GIS is typically related to operations such as map overlay (combining two or more maps or map layers according to predefined rules), simple buffering (identifying regions of a map within a specified distance of one or more features, such as towns, roads or rivers) and similar basic operations. This reflects (and is reflected in) the use of the term spatial analysis within the Open Geospatial Consortium (OGC) “simple feature specifications”. For raster-based GIS, widely used in the environmental sciences and remote sensing, this typically means a range of actions applied to the grid cells of one or more maps (or images) often involving filtering and/or algebraic operations (map algebra). These techniques involve processing one or more raster layers according to simple rules resulting in a new map layer, for example replacing each cell value with some combination of its neighbours’ values, or computing the sum or difference of specific attribute values for each grid cell in two matching raster datasets. Descriptive statistics, such as cell counts, means, variances, maxima, minima, cumulative values, frequencies and a number of other measures and distance computations are also often included in this generic term spatial analysis. Spatial analysis includes a large variety of statistical techniques (descriptive, exploratory, and explanatory statistics) that apply to data that vary spatially and which can vary over time. Some more advanced statistical techniques include Getis-ord Gi* or Anselin Local Moran's I which are used to determine clustering patterns of spatially referenced data.
Advanced operations
editGeospatial and Hydrospatial analysis goes beyond 2D and 3D mapping operations and spatial statistics. It is multi-dimensional and also temporal and includes:
- Surface analysis — in particular analysing the properties of physical surfaces, such as gradient, aspect and visibility, and analysing surface-like data “fields”;
- Network analysis — examining the properties of natural and man-made networks in order to understand the behaviour of flows within and around such networks; and locational analysis. GIS-based network analysis may be used to address a wide range of practical problems such as route selection and facility location (core topics in the field of operations research), and problems involving flows such as those found in Hydrospatial and hydrology and transportation research. In many instances location problems relate to networks and as such are addressed with tools designed for this purpose, but in others existing networks may have little or no relevance or may be impractical to incorporate within the modeling process. Problems that are not specifically network constrained, such as new road or pipeline routing, regional warehouse location, mobile phone mast positioning or the selection of rural community health care sites, may be effectively analysed (at least initially) without reference to existing physical networks. Locational analysis "in the plane" is also applicable where suitable network datasets are not available, or are too large or expensive to be utilised, or where the location algorithm is very complex or involves the examination or simulation of a very large number of alternative configurations.
- Geovisualization — the creation and manipulation of images, maps, diagrams, charts, 3D views and their associated tabular datasets. GIS packages increasingly provide a range of such tools, providing static or rotating views, draping images over 2.5D surface representations, providing animations and fly-throughs, dynamic linking and brushing and spatio-temporal visualisations. This latter class of tools is the least developed, reflecting in part the limited range of suitable compatible datasets and the limited set of analytical methods available, although this picture is changing rapidly. All these facilities augment the core tools utilised in spatial analysis throughout the analytical process (exploration of data, identification of patterns and relationships, construction of models, and communication of results)
Mobile geospatial and hydrospatial Computing
editTraditionally geospatial and hydrospatial computing has been performed primarily on personal computers (PCs) or servers. Due to the increasing capabilities of mobile devices, however, geospatial computing in mobile devices is a fast-growing trend.[74] The portable nature of these devices, as well as the presence of useful sensors, such as Global Navigation Satellite System (GNSS) receivers and barometric pressure sensors, make them useful for capturing and processing geospatial and hydrospatial information in the field. In addition to the local processing of geospatial information on mobile devices, another growing trend is cloud-based geospatial computing. In this architecture, data can be collected in the field using mobile devices and then transmitted to cloud-based servers for further processing and ultimate storage. In a similar manner, geospatial and hydrospatial information can be made available to connected mobile devices via the cloud, allowing access to vast databases of geospatial and hydrospatial information anywhere where a wireless data connection is available.
Geographic information science and spatial analysis
edit
Geographic information systems (GIS) and the underlying geographic information science that advances these technologies have a strong influence on spatial analysis. The increasing ability to capture and handle geographic data means that spatial analysis is occurring within increasingly data-rich environments. Geographic data capture systems include remotely sensed imagery, environmental monitoring systems such as intelligent transportation systems, and location-aware technologies such as mobile devices that can report location in near-real time. GIS provide platforms for managing these data, computing spatial relationships such as distance, connectivity and directional relationships between spatial units, and visualizing both the raw data and spatial analytic results within a cartographic context. Subtypes include:
- Geovisualization (GVis) combines scientific visualization with digital cartography to support the exploration and analysis of geographic data and information, including the results of spatial analysis or simulation. GVis leverages the human orientation towards visual information processing in the exploration, analysis and communication of geographic data and information. In contrast with traditional cartography, GVis is typically three- or four-dimensional (the latter including time) and user-interactive.
- Geographic knowledge discovery (GKD) is the human-centered process of applying efficient computational tools for exploring massive spatial databases. GKD includes geographic data mining, but also encompasses related activities such as data selection, data cleaning and pre-processing, and interpretation of results. GVis can also serve a central role in the GKD process. GKD is based on the premise that massive databases contain interesting (valid, novel, useful and understandable) patterns that standard analytical techniques cannot find. GKD can serve as a hypothesis-generating process for spatial analysis, producing tentative patterns and relationships that should be confirmed using spatial analytical techniques.
- Spatial decision support systems (SDSS) take existing spatial data and use a variety of mathematical models to make projections into the future. This allows urban and regional planners to test intervention decisions prior to implementation.[75]
See also
edit- General topics
- Buffer analysis
- Cartography
- Complete spatial randomness
- Concepts and Techniques in Modern Geography
- Cost distance analysis
- Four traditions of geography
- GeoComputation
- Geospatial intelligence
- Geospatial predictive modeling
- Dimensionally Extended nine-Intersection Model (DE-9IM)
- Geographic information science
- Mathematical statistics
- Modifiable areal unit problem
- Modifiable temporal unit problem
- Neighborhood effect averaging problem
- Point process
- Proximity analysis
- Spatial descriptive statistics
- Spatial relation
- Technical geography
- Terrain analysis
- Tobler's first law of geography
- Tobler's second law of geography
- List of spatial analysis software
- Specific applications
- Boundary problem (in spatial analysis)
- Extrapolation domain analysis
- Fuzzy architectural spatial analysis
- Geodemographic segmentation
- Geographic information systems
- Geoinformatics
- Geostatistics
- Permeability (spatial and transport planning)
- Spatial econometrics
- Spatial epidemiology
- Suitability analysis
- Viewshed analysis
References
edit- ^ The History of Land Surveying. Accessed Dec 17 2020. https://info.courthousedirect.com/blog/history-of-land-surveying
- ^ Mark Monmonier How to Lie with Maps University of Chicago Press, 1996.
- ^ Openshaw, Stan (1983). The Modifiable Areal Unit Problem (PDF). Geo Books. ISBN 0-86094-134-5.
- ^ Chen, Xiang; Ye, Xinyue; Widener, Michael J.; Delmelle, Eric; Kwan, Mei-Po; Shannon, Jerry; Racine, Racine F.; Adams, Aaron; Liang, Lu; Peng, Jia (27 December 2022). "A systematic review of the modifiable areal unit problem (MAUP) in community food environmental research". Urban Informatics. 1 (1): 22. Bibcode:2022UrbIn...1...22C. doi:10.1007/s44212-022-00021-1. S2CID 255206315.
- ^ "MAUP | Definition – Esri Support GIS Dictionary". support.esri.com. Retrieved 2017-03-09.
- ^ Geography, US Census Bureau. "Geographic Boundary Change Notes". www.census.gov. Retrieved 2017-02-24.
- ^ Cheng, Tao; Adepeju, Monsuru; Preis, Tobias (27 June 2014). "Modifiable Temporal Unit Problem (MTUP) and Its Effect on Space-Time Cluster Detection". PLOS ONE. 9 (6): e100465. Bibcode:2014PLoSO...9j0465C. doi:10.1371/journal.pone.0100465. PMC 4074055. PMID 24971885.
- ^ Jong, R. de; Bruin, S. de (5 January 2012). "Linear trends in seasonal vegetation time series and the modifiable temporal unit problem". Biogeosciences. 9 (1): 71–77. Bibcode:2012BGeo....9...71D. doi:10.5194/bg-9-71-2012.
- ^ Deckard, Mica; Schnell, Cory (22 October 2022). "The Temporal (In)Stability of Violent Crime Hot Spots Between Months and The Modifiable Temporal Unit Problem". Crime & Delinquency. 69 (6–7): 1312–1335. doi:10.1177/00111287221128483.
- ^ a b Kwan, Mei-Po (2018). "The Neighborhood Effect Averaging Problem (NEAP): An Elusive Confounder of the Neighborhood Effect". Int J Environ Res Public Health. 15 (9): 1841. doi:10.3390/ijerph15091841. PMC 6163400. PMID 30150510.
- ^ a b Kwan, Mei-Po (2023). "Human Mobility and the Neighborhood Effect Averaging Problem (NEAP)". In Li, Bin; Xun, Shi; A-Xing, Zhu; Wang, Cuizhen; Lin, Hui (eds.). New Thinking in GIScience. Springer. pp. 95–101. doi:10.1007/978-981-19-3816-0_11. ISBN 978-981-19-3818-4. Retrieved 7 October 2023.
- ^ Xu, Tiantian; Wang, Shiyi; Liu, Qing; Kim, Junghwan; Zhang, Jingyi; Ren, Yiwen; Ta, Na; Wang, Xiaoliang; Wu, Jiayu (August 2023). "Vegetation color exposure differences at the community and individual levels: An explanatory framework based on the neighborhood effect averaging problem". Urban Forestry & Urban Greening. 86. Bibcode:2023UFUG...8628001X. doi:10.1016/j.ufug.2023.128001.
- ^ Ham, Maarten van; Manley, David (2012). "Neighbourhood Effects Research at a Crossroads. Ten Challenges for Future Research Introduction". Environment and Planning A: Economy and Space. 44 (12): 2787–2793. doi:10.1068/a4543.
- ^ Parry, Marc (5 November 2012). "The Neighborhood Effect". THE CHRONICLE REVIEW. The Chronicle of Higher Education. Retrieved 7 October 2023.
- ^ Labbé, Martine; Laporte, Gilbert; Martín, Inmaculada Rodríguez; González, Juan José Salazar (May 2004). "The Ring Star Problem: Polyhedral analysis and exact algorithm". Networks. 43 (3): 177–189. doi:10.1002/net.10114. ISSN 0028-3045.
- ^ See the TSP world tour problem which has already been solved to within 0.05% of the optimal solution. [1]
- ^ a b c d Kwan, Mei-Po (2012). "The Uncertain Geographic Context Problem". Annals of the Association of American Geographers. 102 (5): 958–968. doi:10.1080/00045608.2012.687349. S2CID 52024592.
- ^ a b c d Kwan, Mei-Po (2012). "How GIS can help address the uncertain geographic context problem in social science research". Annals of GIS. 18 (4): 245–255. Bibcode:2012AnGIS..18..245K. doi:10.1080/19475683.2012.727867. S2CID 13215965. Retrieved 4 January 2023.
- ^ Matthews, Stephen A. (2017). International Encyclopedia of Geography: People, the Earth, Environment and Technology: Uncertain Geographic Context Problem. Wiley. doi:10.1002/9781118786352.wbieg0599.
- ^ a b Openshaw, Stan (1983). The Modifiable Aerial Unit Problem (PDF). GeoBooks. ISBN 0-86094-134-5.
- ^ a b c Chen, Xiang; Ye, Xinyue; Widener, Michael J.; Delmelle, Eric; Kwan, Mei-Po; Shannon, Jerry; Racine, Racine F.; Adams, Aaron; Liang, Lu; Peng, Jia (27 December 2022). "A systematic review of the modifiable areal unit problem (MAUP) in community food environmental research". Urban Informatics. 1 (1): 22. Bibcode:2022UrbIn...1...22C. doi:10.1007/s44212-022-00021-1. S2CID 255206315.
- ^ a b Gao, Fei; Kihal, Wahida; Meur, Nolwenn Le; Souris, Marc; Deguen, Séverine (2017). "Does the edge effect impact on the measure of spatial accessibility to healthcare providers?". International Journal of Health Geographics. 16 (1): 46. doi:10.1186/s12942-017-0119-3. PMC 5725922. PMID 29228961.
- ^ a b Chen, Xiang; Kwan, Mei-Po (2015). "Contextual Uncertainties, Human Mobility, and Perceived Food Environment: The Uncertain Geographic Context Problem in Food Access Research". American Journal of Public Health. 105 (9): 1734–1737. doi:10.2105/AJPH.2015.302792. PMC 4539815. PMID 26180982.
- ^ Zhou, Xingang; Liu, Jianzheng; Gar On Yeh, Anthony; Yue, Yang; Li, Weifeng (2015). "The Uncertain Geographic Context Problem in Identifying Activity Centers Using Mobile Phone Positioning Data and Point of Interest Data". Advances in Spatial Data Handling and Analysis. Advances in Geographic Information Science. pp. 107–119. doi:10.1007/978-3-319-19950-4_7. ISBN 978-3-319-19949-8.
- ^ Allen, Jeff (2019). "Using Network Segments in the Visualization of Urban Isochrones". Cartographica: The International Journal for Geographic Information and Geovisualization. 53 (4): 262–270. doi:10.3138/cart.53.4.2018-0013. S2CID 133986477.
- ^ Zhao, Pengxiang; Kwan, Mei-Po; Zhou, Suhong (2018). "The Uncertain Geographic Context Problem in the Analysis of the Relationships between Obesity and the Built Environment in Guangzhou". International Journal of Environmental Research and Public Health. 15 (2): 308. doi:10.3390/ijerph15020308. PMC 5858377. PMID 29439392.
- ^ Zhou, Xingang; Liu, Jianzheng; Yeh, Anthony Gar On; Yue, Yang; Li, Weifeng (2015). "The Uncertain Geographic Context Problem in Identifying Activity Centers Using Mobile Phone Positioning Data and Point of Interest Data". Advances in Spatial Data Handling and Analysis. Advances in Geographic Information Science. pp. 107–119. doi:10.1007/978-3-319-19950-4_7. ISBN 978-3-319-19949-8. Retrieved 22 January 2023.
- ^ Tobler, Waldo (2004). "On the First Law of Geography: A Reply". Annals of the Association of American Geographers. 94 (2): 304–310. doi:10.1111/j.1467-8306.2004.09402009.x. S2CID 33201684. Retrieved 10 March 2022.
- ^ Salvo, Deborah; Durand, Casey P.; Dooley, Erin E.; Johnson, Ashleigh M.; Oluyomi, Abiodun; Gabriel, Kelley P.; Van Dan Berg, Alexandra; Perez, Adriana; Kohl, Harold W. (June 2019). "Reducing the Uncertain Geographic Context Problem in Physical Activity Research: The Houston TRAIN Study". Medicine & Science in Sports & Exercise. 51 (6S): 437. doi:10.1249/01.mss.0000561808.49993.53. S2CID 198375226.
- ^ Thrift, Nigel (1977). An Introduction to Time-Geography (PDF). Geo Abstracts, University of East Anglia. ISBN 0-90224667-4.
- ^ Shmool, Jessie L.; Johnson, Isaac L.; Dodson, Zan M.; Keene, Robert; Gradeck, Robert; Beach, Scott R.; Clougherty, Jane E. (2018). "Developing a GIS-Based Online Survey Instrument to Elicit Perceived Neighborhood Geographies to Address the Uncertain Geographic Context Problem". The Professional Geographer. 70 (3): 423–433. Bibcode:2018ProfG..70..423S. doi:10.1080/00330124.2017.1416299. S2CID 135366460. Retrieved 22 January 2023.
- ^ Journel, A G and Huijbregts, C J, Mining Geostatistics, Academic Press Inc, London.
- ^ von Csefalvay, Chris (2023), "Spatial dynamics of epidemics", Computational Modeling of Infectious Disease, Elsevier, pp. 257–303, doi:10.1016/b978-0-32-395389-4.00017-7, ISBN 978-0-323-95389-4, retrieved 2023-03-05
- ^ Knegt, De; Coughenour, M.B.; Skidmore, A.K.; Heitkönig, I.M.A.; Knox, N.M.; Slotow, R.; Prins, H.H.T. (2010). "Spatial autocorrelation and the scaling of species–environment relationships". Ecology. 91 (8): 2455–2465. Bibcode:2010Ecol...91.2455D. doi:10.1890/09-1359.1. PMID 20836467.
- ^ "Spatial Association" (PDF). Geography Teachers' Association of Victoria. Retrieved 17 November 2014.
- ^ Song, Yongze (July 2022). "The second dimension of spatial association". International Journal of Applied Earth Observation and Geoinformation. 111: 102834. doi:10.1016/j.jag.2022.102834. hdl:20.500.11937/88649. S2CID 249166886.
- ^ Halley, J. M.; Hartley, S.; Kallimanis, A. S.; Kunin, W. E.; Lennon, J. J.; Sgardelis, S. P. (2004-03-01). "Uses and abuses of fractal methodology in ecology". Ecology Letters. 7 (3): 254–271. Bibcode:2004EcolL...7..254H. doi:10.1111/j.1461-0248.2004.00568.x. ISSN 1461-0248.
- ^ Ocaña-Riola, R (2010). "Common errors in disease mapping". Geospatial Health. 4 (2): 139–154. doi:10.4081/gh.2010.196. PMID 20503184.
- ^ a b c d e f "Understanding Spatial Fallacies". The Learner's Guide to Geospatial Analysis. Penn State Department of Geography. Retrieved 27 April 2018.
- ^ Quattrochi, Dale A (2016-02-01). Integrating scale in remote sensing and GIS. Taylor & Francis. ISBN 9781482218268. OCLC 973767077.
- ^ Robinson, Ws (April 2009). "Ecological Correlations and the Behavior of Individuals*". International Journal of Epidemiology. 38 (2): 337–341. doi:10.1093/ije/dyn357. PMID 19179346.
- ^ Graham J. Upton & Bernard Fingelton: Spatial Data Analysis by Example Volume 1: Point Pattern and Quantitative Data John Wiley & Sons, New York. 1985.
- ^ Harman H H (1960) Modern Factor Analysis, University of Chicago Press
- ^ Rummel R J (1970) Applied Factor Analysis. Evanston, ILL: Northwestern University Press.
- ^ Bell W & E Shevky (1955) Social Area Analysis, Stanford University Press
- ^ Moser C A & W Scott (1961) British Towns; A Statistical Study of their Social and Economic Differences, Oliver & Boyd, London.
- ^ Berry B J & F Horton (1971) Geographic Perspectives on Urban Systems, John Wiley, N-Y.
- ^ Berry B J & K B Smith eds (1972) City Classification Handbook : Methods and Applications, John Wiley, N-Y.
- ^ Ciceri M-F (1974) Méthodes d’analyse multivariée dans la géographie anglo-saxonne, Université de Paris-1; free download on http://www-ohp.univ-paris1.fr
- ^ Tucker L R (1964) « The extension of Factor Analysis to three-dimensional matrices », in Frederiksen N & H Gulliksen eds, Contributions to Mathematical Psychology, Holt, Rinehart and Winston, NY.
- ^ R. Coppi & S. Bolasco, eds. (1989), Multiway data analysis, Elsevier, Amsterdam.
- ^ Cant, R.G. (1971). "Changes in the location of manufacturing in New Zealand 1957-1968: An application of three-mode factor analysis". New Zealand Geographer. 27 (1): 38–55. Bibcode:1971NZGeo..27...38C. doi:10.1111/j.1745-7939.1971.tb00636.x.
- ^ Marchand B (1986) The Emergence of Los Angeles, 1940-1970, Pion Ltd, London
- ^ Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. (1996). "Geographically Weighted Regression: A Method for Exploring Spatial Nonstationarity". Geographical Analysis. 28 (4): 281–298. Bibcode:1996GeoAn..28..281B. doi:10.1111/j.1538-4632.1996.tb00936.x.
- ^ a b Banerjee, Sudipto; Carlin, Bradley P.; Gelfand, Alan E. (2014), Hierarchical Modeling and Analysis for Spatial Data, Second Edition, Monographs on Statistics and Applied Probability (2nd ed.), Chapman and Hall/CRC, ISBN 9781439819173
- ^ Bivand, Roger (20 January 2021). "CRAN Task View: Analysis of Spatial Data". Retrieved 21 January 2021.
- ^ Banerjee, Sudipto; Gelfand, Alan E.; Finley, Andrew O.; Sang, Huiyan (2008). "Gaussian predictive process models for large spatial datasets". Journal of the Royal Statistical Society, Series B. 70 (4): 825–848. doi:10.1111/j.1467-9868.2008.00663.x. PMC 2741335. PMID 19750209.
- ^ Datta, Abhirup; Banerjee, Sudipto; Finley, Andrew O.; Gelfand, Alan E. (2016). "Hierarchical Nearest Neighbor Gaussian Process Models for Large Geostatistical Datasets". Journal of the American Statistical Association. 111 (514): 800–812. arXiv:1406.7343. doi:10.1080/01621459.2015.1044091. PMC 5927603. PMID 29720777.
- ^ Morer I, Cardillo A, Díaz-Guilera A, Prignano L, Lozano S (2020). "Comparing spatial networks: a one-size-fits-all efficiency-driven approach". Physical Review. 101 (4): 042301. Bibcode:2020PhRvE.101d2301M. doi:10.1103/PhysRevE.101.042301. hdl:2445/161417. PMID 32422764. S2CID 49564277.
- ^ Gupta J, Molnar C, Xie Y, Knight J, Shekhar S (2021). "Spatial variability aware deep neural networks (SVANN): a general approach". ACM Transactions on Intelligent Systems and Technology. 12 (6): 1–21. doi:10.1145/3466688. S2CID 244786699.
- ^ Hagenauer J, Helbich M (2022). "A geographically weighted artificial neural network". International Journal of Geographical Information Science. 36 (2): 215–235. Bibcode:2022IJGIS..36..215H. doi:10.1080/13658816.2021.1871618. S2CID 233883395.
- ^ Silva, E. A.; Clarke, K.C. (2002). "Calibration of the SLEUTH urban growth model for Lisbon and Porto, Portugal". Computers, Environment and Urban Systems. 26 (6): 525–552. Bibcode:2002CEUS...26..525S. doi:10.1016/S0198-9715(01)00014-X.
- ^ Silva, E A (2003). "Complexity, emergence and cellular urban models: lessons learned from applying SLEUTH to two Portuguese metropolitan areas". European Planning Studies. 13 (1): 93–115. doi:10.1080/0965431042000312424. S2CID 197257.
- ^ Liu and Silva (2017). "Examining the dynamics of the interaction between the development of creative industries and urban spatial structure by agent-based modelling: A case study of Nanjing, China". Urban Studies. 65 (5): 113–125. doi:10.1177/0042098016686493. S2CID 157318972.
- ^ Liu, Lun; Silva, Elisabete A.; Wu, Chunyang; Wang, Hui (2017). "A machine learning-based method for the large-scale evaluation of the qualities of the urban environment" (PDF). Computers Environment and Urban Systems. 65: 113–125. Bibcode:2017CEUS...65..113L. doi:10.1016/j.compenvurbsys.2017.06.003.
- ^ Honarkhah, M; Caers, J (2010). "Stochastic Simulation of Patterns Using Distance-Based Pattern Modeling". Mathematical Geosciences. 42 (5): 487–517. Bibcode:2010MaGeo..42..487H. doi:10.1007/s11004-010-9276-7. S2CID 73657847.
- ^ Tahmasebi, P.; Hezarkhani, A.; Sahimi, M. (2012). "Multiple-point geostatistical modeling based on the cross-correlation functions". Computational Geosciences. 16 (3): 779–79742. Bibcode:2012CmpGe..16..779T. doi:10.1007/s10596-012-9287-1. S2CID 62710397.
- ^ Tahmasebi, P.; Sahimi, M. (2015). "Reconstruction of nonstationary disordered materials and media: Watershed transform and cross-correlation function". Physical Review E. 91 (3): 032401. Bibcode:2015PhRvE..91c2401T. doi:10.1103/PhysRevE.91.032401. PMID 25871117.
- ^ Tahmasebi, P.; Sahimi, M. (2015). "Geostatistical Simulation and Reconstruction of Porous Media by a Cross-Correlation Function and Integration of Hard and Soft Data". Transport in Porous Media. 107 (3): 871–905. Bibcode:2015TPMed.107..871T. doi:10.1007/s11242-015-0471-3. S2CID 123432975.
- ^ "Graduate Program in Spatial Analysis". Ryerson University. Retrieved 17 December 2015.
- ^ geospatial. Collins English Dictionary - Complete & Unabridged 11th Edition. Retrieved 5tth August 2012 from CollinsDictionary.com website: http://www.collinsdictionary.com/dictionary/english/geospatial
- ^ Dictionary.com's 21st Century Lexicon Copyright © 2003-2010 Dictionary.com, LLC http://dictionary.reference.com/browse/geospatial
- ^ The geospatial web – blending physical and virtual spaces. Archived 2011-10-02 at the Wayback Machine, Arno Scharl in receiver magazine, Autumn 2008
- ^ Chen, Ruizhi; Guinness, Robert E. (2014). Geospatial Computing in Mobile Devices (1st ed.). Norwood, MA: Artech House. p. 228. ISBN 978-1-60807-565-2. Retrieved 1 July 2014.
- ^ González, Ainhoa; Donnelly, Alison; Jones, Mike; Chrysoulakis, Nektarios; Lopes, Myriam (2012). "A decision-support system for sustainable urban metabolism in Europe". Environmental Impact Assessment Review. 38: 109–119. doi:10.1016/j.eiar.2012.06.007.
Further reading
editThis "Further reading" section may need cleanup. (June 2014) |
- Abler, R., J. Adams, and P. Gould (1971) Spatial Organization–The Geographer's View of the World, Englewood Cliffs, NJ: Prentice-Hall.
- Anselin, L. (1995) "Local indicators of spatial association – LISA". Geographical Analysis, 27, 93–115.
- Awange, Joseph; Paláncz, Béla (2016). Geospatial Algebraic Computations, Theory and Applications, Third Edition. New York: Springer. ISBN 978-3319254630.
- Banerjee, Sudipto; Carlin, Bradley P.; Gelfand, Alan E. (2014), Hierarchical Modeling and Analysis for Spatial Data, Second Edition, Monographs on Statistics and Applied Probability (2nd ed.), Chapman and Hall/CRC, ISBN 9781439819173
- Benenson, I. and P. M. Torrens. (2004). Geosimulation: Automata-Based Modeling of Urban Phenomena. Wiley.
- Fotheringham, A. S., C. Brunsdon and M. Charlton (2000) Quantitative Geography: Perspectives on Spatial Data Analysis, Sage.
- Fotheringham, A. S. and M. E. O'Kelly (1989) Spatial Interaction Models: Formulations and Applications, Kluwer Academic
- Fotheringham, A. S.; Rogerson, P. A. (1993). "GIS and spatial analytical problems". International Journal of Geographical Information Systems. 7: 3–19. doi:10.1080/02693799308901936.
- Goodchild, M. F. (1987). "A spatial analytical perspective on geographical information systems". International Journal of Geographical Information Systems. 1 (4): 327–44. doi:10.1080/02693798708927820.
- MacEachren, A. M. and D. R. F. Taylor (eds.) (1994) Visualization in Modern Cartography, Pergamon.
- Levine, N. (2010). CrimeStat: A Spatial Statistics Program for the Analysis of Crime Incident Locations. Version 3.3. Ned Levine & Associates, Houston, TX and the National Institute of Justice, Washington, DC. Ch. 1-17 + 2 update chapters
- Miller, H. J. (2004). "Tobler's First Law and spatial analysis". Annals of the Association of American Geographers. 94 (2): 284–289. doi:10.1111/j.1467-8306.2004.09402005.x. S2CID 19172678.
- Miller, H. J. and J. Han (eds.) (2001) Geographic Data Mining and Knowledge Discovery, Taylor and Francis.
- O'Sullivan, D. and D. Unwin (2002) Geographic Information Analysis, Wiley.
- Parker, D. C.; Manson, S. M.; Janssen, M.A.; Hoffmann, M. J.; Deadman, P. (2003). "Multi-agent systems for the simulation of land-use and land-cover change: A review". Annals of the Association of American Geographers. 93 (2): 314–337. CiteSeerX 10.1.1.109.1825. doi:10.1111/1467-8306.9302004. S2CID 130096094.
- White, R.; Engelen, G. (1997). "Cellular automata as the basis of integrated dynamic regional modelling". Environment and Planning B: Planning and Design. 24 (2): 235–246. Bibcode:1997EnPlB..24..235W. doi:10.1068/b240235. S2CID 62516646.
- Scheldeman, X. & van Zonneveld, M. (2010). Training Manual on Spatial Analysis of Plant Diversity and Distribution. Bioversity International.
- Fisher MM, Leung Y (2001) Geocomputational Modelling: techniques and applications. Springer Verlag, Berlin
- Fotheringham, S; Clarke, G; Abrahart, B (1997). "Geocomputation and GIS". Transactions in GIS. 2 (3): 199–200. doi:10.1111/j.1467-9671.1997.tb00010.x. S2CID 205576122.
- Openshaw S and Abrahart RJ (2000) GeoComputation. CRC Press
- Diappi Lidia (2004) Evolving Cities: Geocomputation in Territorial Planning. Ashgate, England
- Longley PA, Brooks SM, McDonnell R, Macmillan B (1998), Geocomputation, a primer. John Wiley and Sons, Chichester
- Ehlen, J; Caldwell, DR; Harding, S (2002). "GeoComputation: what is it?". Comput Environ and Urban Syst. 26 (4): 257–265. Bibcode:2002CEUS...26..257E. doi:10.1016/s0198-9715(01)00047-3.
- Gahegan, M (1999). "What is Geocomputation?". Transactions in GIS. 3 (3): 203–206. doi:10.1111/1467-9671.00017. S2CID 44656909.
- Murgante B., Borruso G., Lapucci A. (2009) "Geocomputation and Urban Planning" Studies in Computational Intelligence, Vol. 176. Springer-Verlag, Berlin.
- Reis, José P.; Silva, Elisabete A.; Pinho, Paulo (2016). "Spatial metrics to study urban patterns in growing and shrinking cities". Urban Geography. 37 (2): 246–271. doi:10.1080/02723638.2015.1096118. S2CID 62886095.
- Papadimitriou, F. (2002). "Modelling indicators and indices of landscape complexity: An approach using G.I.S". Ecological Indicators. 2 (1–2): 17–25. Bibcode:2002EcInd...2...17P. doi:10.1016/S1470-160X(02)00052-3.
- Fischer M., Leung Y. (2010) "GeoComputational Modelling: Techniques and Applications" Advances in Spatial Science. Springer-Verlag, Berlin.
- Murgante B., Borruso G., Lapucci A. (2011) "Geocomputation, Sustainability and Environmental Planning" Studies in Computational Intelligence, Vol. 348. Springer-Verlag, Berlin.
- Tahmasebi, P.; Hezarkhani, A.; Sahimi, M. (2012). "Multiple-point geostatistical modeling based on the cross-correlation functions". Computational Geosciences. 16 (3): 779–79742. Bibcode:2012CmpGe..16..779T. doi:10.1007/s10596-012-9287-1. S2CID 62710397.
- Geza, Tóth; Áron, Kincses; Zoltán, Nagy (2014). European Spatial Structure. LAP LAMBERT Academic Publishing. doi:10.13140/2.1.1560.2247.
External links
edit- ICA Commission on Geospatial Analysis and Modeling
- An educational resource about spatial statistics and geostatistics
- A comprehensive guide to principles, techniques & software tools
- Social and Spatial Inequalities
- National Center for Geographic Information and Analysis (NCGIA)
- International Cartographic Association (ICA) – the world body for mapping and GIScience professionals