Talk:Linear regression
| This is the talk page for discussing improvements to the Linear regression article. This is not a forum for general discussion of the article's subject. |
Article policies
|
| Find sources: Google (books · news · scholar · free images · WP refs) · FENS · JSTOR · TWL |
| Archives: 1 |
| This It is of interest to the following WikiProjects: | |||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||



Endogenous/exogenous
editThe uses of "endogenous" and "exogenous" variables here are not consistent with the only way I've ever heard them used. Exogenous means outside of the model -- i.e., a latent/hidden variable. Endogenous describes a variable that IS accounted for by your model, be it independent OR dependent. See Wiki entry for "exogenous," which supports this.
I recommend that these two words be deleted from the list of alternate names for predictor and criterion variables. (unsigned comments by 72.87.187.241)
- I have found economists use exogenous in lenear models to mean non response variables. The contrast is endogenous variables that appear on the right hand side of one or more other variables equations but also on the left hand side of their own regression. Pdbailey 00:06, 7 October 2006 (UTC)
- In economics exogenous means something determined outside of the model, such as X which is determined by God, or random chance, or anything but not the model itself. On the other hand Y is endogenous, since it is determined within the model, via the equation Y = Xβ + ε. This terminology becomes more useful when discussing simultaneous equations models. Also within the context of IV whenever one of the X's is correlated with ε's we will call such X endogenous as well. Stpasha (talk) 19:10, 30 June 2009 (UTC)
I would like to add that in economic models there is another type of variable: the predetermined variable. Pre-determined variables, as the name implied, are often lagged endogenous variables or lagged dependent variables. —Preceding unsigned comment added by Daonng (talk • contribs) 06:54, 10 May 2011 (UTC)
Name: Regression? Or Linear Models, or Linear Statistical Models, etc.
editThere are substantial portions of the literature which have moved away from the use of the term "regression". The term "regression" is used for historical reasons but does not capture the meaning of what is actually going on.
Terms such as "Linear Models", "Linear Statistical Models" are becoming at least as widely used as "linear regression" in the literature, and their meaning is more descriptive of what is actually going on. I think we ought to consider renaming this article and have "Linear regression" forward to the new page. At the very least, we ought to discuss the issues regarding naming on this page. Cazort 19:24, 17 October 2007 (UTC)
- The term 'linear model' is wider than 'linear regression' as the latter implies that the predictor variable is numeric, while the former allows for numeric or categorical variables (i.e. an analysis of variance model.) Blaise (talk) 13:07, 31 March 2013 (UTC)
- I agree --Forich (talk) 11:46, 13 June 2017 (UTC)
Regression articles discussion July 2009
editA discussion of content overlap of some regression-related articles has been started at Talk:Linear least squares#Merger proposal but it isn't really just a question of merging and no actual merge proposal has been made. Melcombe (talk) 11:33, 14 July 2009 (UTC)
Rename?
editDear All,
- I wonder what do you all think about renaming this article into the Linear regression model? It seems to me that such name better expresses the topic of the article: some people use the word “regression” to refer to the process of estimation, while for others “regression” means the statistical model itself; however combination “regression model” is unambiguous. ... stpasha » talk » 01:17, 21 July 2009 (UTC)
Generally I prefer shorter titles, but I will think about this one. Michael Hardy (talk) 02:00, 21 July 2009 (UTC)
- I reopened this topic for discussion at the WPStatistics talk page. Please leave your comments there. // stpasha » 23:54, 21 April 2010 (UTC)
Merge Trend estimation to here
editThe article Trend estimation does not go beyond linear models and contains much that is actually generic for linear regression and dealt with better here. It appears to me that Trend estimation could simply become a redirect to Linear regression#Trend line (which might be renamed Linear regression#Trend estimation) after merging any useful stuff from there to here. --Lambiam 19:17, 27 July 2009 (UTC)
- I think it would be better left separate, but changed to better reflect actual trend estimation rather than saying it is essentially equivalent to least squares regression, which it shouldn't be. Melcombe (talk) 10:50, 29 July 2009 (UTC)
- But who is going to execute that change and when? Don't you agree that until someone actually creates an article on trend estimation going beyond linear regression to find a trend line (which is more specialized than least squares regression, which might apply to other than linear trend models), the reader is better served by the proposed redirect? --Lambiam 12:48, 2 August 2009 (UTC)
- I agree with Nelcombe 78.86.230.145 (talk) 14:13, 9 September 2009 (UTC)
But, isn't Linear regression just a tool used in Trend estimation? How can the over-arcing topic be listed under a tool? It would be like putting an on trees or woodworking in another article talking only about hammers. You use hammers to work wood, but you also use saws and other things that don't fit under the category of hammers. However, saws and the other tools are key to woodworking. Therefor, just put a link for Trend estimation at the bottom of the Linear regression page. if people want to read it, they can click the link. ~ Talon SFSU 12 September 2009
>But, isn't Linear regression just a tool used in Trend estimation?
No, it isn't. It's a very general model for data. Trend estimation is just one application. Interpolation is another. Also, multilevel models (random effects) can be viewed as consisting of composed of multiple linear regression models. Blaise (talk) 13:14, 31 March 2013 (UTC)
Typography Disambiguation
editThe ' character is used in several different contexts without clarification.
e.g:
http://upload.wikimedia.org/math/8/2/5/8255bd19aeed347fd8173d8038eb71ad.png aggregation
http://upload.wikimedia.org/math/6/8/3/683c3fe809a780a8bca83553bf0f6921.png transposition?
The contextual meaning of the character should be explicitly stated, whether it means "Transpose" or is used to aggregate individual variables into rows and vectors.
Use of T notation is less ambiguous in all cases.
--67.198.45.12 (talk) 14:38, 30 July 2009 (UTC)Matt Fowler
- I think it means transposition either way. Michael Hardy (talk) 17:10, 30 July 2009 (UTC)
- aah i see, they dropped the second subscript to denote the entire row.
- so still the confusion derives from a lack of explicit definition of the typography!
- The article states that is a p-vector in the first sentence of Definition section; then it defines ’ notation right after the formula: it says “ is an inner product between two vectors”. Maybe we could state that ’ is transposition more explicitly.
- As for T notation, it isn’t less ambiguous as it could be misunderstood for raising the matrix to the T-th power. ... stpasha » talk » 14:52, 31 July 2009 (UTC)


Re: Assumptions
editAmadhila leonard a student from the University of Namibia(Ogongo Campus) think this could be written to be more usable to more people, along the lines of the following:
- 1) Linear relationship between independent and dependent variable(s)
- How to Check: Make an XY scatter plot, then look for data grouping along a line,instead of along a curve.
- 2) Homoskedastic, meaning that, as independent variables change, errors do not tend to get bigger or smaller.
- How to Check: a residual plot is symmetric, or points on an XY scatter plot do not tend to spread toward the left, or toward the right.
- 3) Normal Distribution of Data, which meets the three following conditions:
- a) Unimodal:
- How to Check: Make a histogram, then look for only one major peak, instead of many.
- b) Symmetric, or Unskewed Data Distribution:
- How to Check: Make that histogram, then compare the left and right tails for size, etc.
- c) Kurtosis is about Zero:
- How to Check: Make that histogram, then compare its peakedness to a normal distribution.
Briancady413 (talk) 19:53, 4 November 2009 (UTC)
- These assumptions are unnecessary for the linear regression, that is, they are too strong. Well, except for the first one. But “making an XY scatterplot” recipe really works only in case of a simple linear regression. Besides, the approach suggested here contradicts the WP:NOTHOWTO(1) policy. … stpasha » 19:52, 30 November 2009 (UTC)
- I agree with Stpasha. I like the assumptions as they are now, because they are valid for the general case of linear regression, whatever the method of estimation or underlying statistical model at hand. --Forich (talk) 22:24, 30 November 2009 (UTC)ndersta
- Isn't normally distributed errors a required assumption of linear regression or does that also fall into the bucket of a special case as opposed to the general case being outlined? — Preceding unsigned comment added by 207.173.178.34 (talk) 17:34, 11 February 2015 (UTC)
Assumption 1) has been misunderstood here (but not in the article) to mean a linear relationship between X and Y. That's not what's meant by linear. If Y is proportional to X^2 it's still a linear model, because Y is linearly related to the betas. THAT'S the relationship that must be linear. Also, in the usual case Y is normally distributed (the X's don't have to be) and this implies unimodality, symmetry and kurtosis equals zero. Blaise (talk) 13:23, 31 March 2013 (UTC)
This article, as with virtually all mathematically-oriented articles on Wikipedia, has been written BY and FOR people who already know the material but are struggling with communicating the material. What the group of you has forgotten is that people who come to Wikipedia are NOT mathematics experts (real or self-imagined)and need a clear explanation of the subject. This article is so filled with jargon and links to other pages that the process of trying to form an understanding of the subject is nearly impossible. Please think about this, consider translating this material for the audience that uses Wikipedia. Before I am condescended to by the mathematical cognoscenti, I will merely observe that I hold a Ph.D. myself, albeit in a different field. Give it some thought folks! — Preceding unsigned comment added by 50.164.122.229 (talk) 00:23, 19 June 2014 (UTC)
I absolutely agree with the previous comment. This article is not understandable by anyone who does not already know what is going on. In particular, I suggest it be written without matrix notation; anyone who understand matrix notation will just look it up in the textbook they learned matrix notation from. This is an important topic for many people who have no idea what a matrix is - and shouldn't need to learn about matrices to understand it. (Despite the fact that it is so "simple" using matrices - if you already know matrices.) David Poole (talk) 10:51, 29 January 2015 (UTC)
Example in the introductory section
editShouldn't it be mentioned in the example paragraph that, in general, predictor variables of type x, x^2, x^3 a.s.o. are mutually correlated? I know that this recipe is frequently given, but I think interpreting the results without accounting for these correlations makes it a dangerous recipe. Perhaps, a hint on how to normalize variables to a certain interval (which might be useful from numerical reasons, too) and on how to use a set of independent polynomials on that interval might be provided. Of course, interpreting the resulting coefficients may be much more complex. ChaosSchorsch (talk) 17:42, 18 February 2010 (UTC)
Epidemiology example
editI am a bit confused by the inclusion of the example of tobacco smoking given in the section on applications of linear regression. Is it not more likely that the model used in these analyses was logistic regression?Jimjamjak (talk) 15:03, 26 March 2010 (UTC)
- The specific nature of the dependent variable is not given. If it were lifespan (measured in years), then linear regression would be perfectly appropriate. If it were "ever diagnosed with lung cancer" then it would probably be a logistic regression analysis. But the points made in this section mainly focus on issues with observational studies versus randomized experiments. So this is not a major point here. Skbkekas (talk) 23:07, 26 March 2010 (UTC)
A line has form y=mx + b, where m is the slope and b is the y-intercept. The current exposition seems to assume that the y-intercept is zero in all cases; that is, it says the form of the points is y_i = beta * x_i + epsilon_i, where epsilon_i is the "noise". There is no mention of the y-intercept, so it looks to me like the data is assumed to be centered at the origin. However, the figure at the top of the page clearly shows that the best-fit line does not need to pass through the origin. So what am I missing? —Preceding unsigned comment added by 86.141.197.132 (talk) 21:55, 6 April 2010 (UTC)
There is no mention of the y-intercept? See the section that begins "Usually a constant is included as one of the regressors." Skbkekas (talk) 12:20, 7 April 2010 (UTC)
Likely inaccurate portrayal of weighted linear regression
editQuote: "GLS can be viewed as applying a linear transformation to the data so that the assumptions of OLS are met for the transformed data. "
This seems to be incorrect. Firstly, because a linear transformation of the data cannot make it meet the assumptions for OLS, and secondly because the introduction of the weights into the equation does not correspond to a linear transformation of the *data*. The intuitive explanation of weighted linear regression that makes sense to me is that higher weighted data items have more impact on the result, as if they were replicated in the data set, but there may be better explanations than that. Grevillea (talk) 04:22, 20 April 2010 (UTC)
- You take the linear regression equation and multiply it by a constant . Then you apply OLS to the transformed data: . In this regression η is already homoscedastic, so the "assumptions of OLS" are met. // stpasha » 09:09, 20 April 2010 (UTC)



- The above argument is only relevant if all the elements of Ω are known, otherwise the new "observations" depend on unknown parameters, and often Ω is not fully known. While, for the simplest applications of "weighted regression", the weights may be known, this is not always the case (depending on exactly how "weighted regression is defined"): however, even in this case, the idea of "replicated observations" doesn't fully work because of the difficulty of treating factional observations. In the "transformation approach", the idea of "more highly weighted observations" is treated by taking the initial formal regression model, in which an observation has an error variance which is smaller than for others, and creating the transformed model in which the regression equation for that observation is replaced by one in which each term (observation, dependent variables and error) in multiplied by a factor such that the new error term (factor × old error) has a constant variance across observations. Melcombe (talk) 16:27, 17 May 2010 (UTC)
Should this article be renamed?
edit- User:Stpasha has proposed renaming this article, from linear regression to linear regression model. (He mentioned this in a thread higher up on this page where no on is likely to see it.) The discussion is at Wikipedia_talk:WikiProject_Statistics#Rename_suggestion. Michael Hardy (talk) 23:33, 22 April 2010 (UTC)
- I have placed a move request to revert the change that was made change the name to linear regression model without any backing here or on the Stats project talk page, and in the face of a previous revert of the same change. See [requests]. Melcombe (talk) 12:59, 17 May 2010 (UTC)
Move?
edit- The following discussion is an archived discussion of a requested move. Please do not modify it. Subsequent comments should be made in a new section on the talk page. No further edits should be made to this section.
The result of the move request was: page moved. I did move the dab page to preserve the edit history and make it available if it is decided to use that in addition to the hat note (which needs adding). Also the previous moves left some archives scattered around. These are, I think, all at the dab page. I'll leave it to the editors here to move those back if that is correct. If you need an admin to do the moves, leave me a note on my talk page about what needs to happen. Vegaswikian (talk) 03:49, 11 June 2010 (UTC)
Linear regression model → Linear regression — Relisted to allow the last comment a chance to see if that is a consensus. Vegaswikian (talk) 02:20, 4 June 2010 (UTC)
Relisted. Arbitrarily0 (talk) 14:16, 25 May 2010 (UTC)
- Previous name change not backed on talk pages mentioned and the same change was previously reverted (21 April) by a 3rd editor for good reason Melcombe (talk) 12:10, 17 May 2010 (UTC)
- I have reverted page Linear regression to a disambig page. See discussion at Talk:Linear regression#Reverted to redirect. Anthony Appleyard (talk) 14:22, 17 May 2010 (UTC)
- Oppose. The topic was discussed on WPStatistics discussion thread, and all arguments were listed there. The reason why the same edit was previously reverted was that “the shorter name is more likely to be linked”, which I see as an argument in favor of the current name. Too often people link to “linear regression” while in fact they meant to link to OLS. // stpasha » 20:17, 17 May 2010 (UTC)
- Support The most common meaning being linked to is a form of linear regression is it not? It would be better to use the simpler title for the general method and just use a hatnote to help readers looking for the specific implementation of linear regression. This would probably even help people realize that there are many systems of linear regression. --Polaron | Talk 14:53, 27 May 2010 (UTC)
This discussion won't go anywhere, at least not without the clear statement of the arguments in favor of the name change. The discussion preceding changing this article's title into “Linear regression model” is quite old — its traces can be found on this talk page, talk pages of other linear regression articles, and at the WPStatistics discussion board. The conclusion from those debates was that we need to restructure the coverage of the linear regression topics, — starting from clearly delineating what the topic of each article is. This is why the name was changed from linear regression into linear regression model — because it is unambiguous and people are less likely to add irrelevant material to it. In contrast, the linear regression article is currently a disambiguation page, exactly because that name is ambiguous. On Wikipedia the titles of the articles strive to be not the shortest, nor the most common — but most precise and least ambiguous. The convenience is secondary, and is achieved through redirects. // stpasha » 20:07, 28 May 2010 (UTC)
- Comment - Since there doesn't seem to be an effective consensus to keep Linear regression a dab page, perhaps it would make sense to add a hatnote to the top of this article, helping people locate the OLS article? -GTBacchus(talk) 16:02, 2 June 2010 (UTC)
- Comment - I'm having trouble following this conversation, but feel like I have a stake in this decision. I thought Wikipedia tried to use the most common naming for articles, so my feeling is that the article should be Linear regression, not Linear regression model. Linear regression is hands down the term used in the non-mathematical community. To appease the statisticians, the hatnote idea sounds appropriate, with the hatnote either redirecting to a specific page, or a disambig page for the general notion of linear regression. I have no idea what an OLS is (perhaps "ordinary least squares"?), but it should at a minimum be spelled out for this discussion. As a general regression model framework would be inaccessible and unnecessary for 99% of users, I sincerely hope that the page accessible by default is a special case model, with only one independent variable, and least squares error estimation. I also hope there is an article for General linear model, another term I hear used in slightly more advanced contexts, but probably not sufficiently advanced for statisticians. 70.250.178.31 (talk) 04:50, 7 June 2010 (UTC)
- The above discussion is preserved as an archive of a requested move. Please do not modify it. Subsequent comments should be made in a new section on this talk page. No further edits should be made to this section.
First sentence
editShould "linear regression" be simply "regression" in the first sentence? As written, it doesn't specify anything that requires linearity.205.248.102.81 (talk) 23:06, 10 September 2010 (UTC)
- No. The sentence is the topic sentence of a paragraph that defines the term. 018 (talk) 23:33, 10 September 2010 (UTC)
- What I meant was that the phrase "any approach to modeling the relationship between a scalar variable y and one or more variables denoted X" sounds like the definition of regression, not the definition of linear regression. —Preceding unsigned comment added by 205.248.102.81 (talk) 00:31, 14 September 2010 (UTC)
I agree with the elimination of the word "linear". To support my agreement, the following reasons are given: (i) Linearity or straight lines are pure human imagination, there is no such thing as a straight line in nature; and (ii) Linearity leads to many misunderstandings of models used in statistical or econometric research, resulting in many misspecified models followed by the downgrading of statistical and econometric models based on time series. A gravest misspecification of statistical and econometric models often cited in literature is the introduction of a "linear time trend" which is one of the most famous "unknown" in statistical models yet it appears most often and has been criticized most often. These critics have stimulated many econometricians in their search of more creative approaches in modelling to avoid the use of the "linear time trend" in the estimation of time series models. One of the novel approaches involve unit root tests and cointegration technique in econometric. In fact,when a linear time trend (represented by the variable To, To+1, To+2,...,To+n; with To is the time base and n is the number of observations), the estimated coefficient associated with this linear time trend variable is often interpreted as a measure of the impact of a number of known and unknown unmeasurable factors (subjectively, as a matter of fact)on the dependent variable in one unit of time. Logically, and strictly speaking, that interpretation is applicable to the estimation time periods only. Outside the estimation periods, one does not know how those unmeasurable factors behave both qualitatively and quantitatively. Furthermore, the linearity of the time trend poses many questions: (i) why should it be linear? (ii) if the trend is non-linear then under what conditions its inclusion does not influence the magnitude as well as the statistical significance of the estimates for other parameters in the model? (iii) the law of nature, especially in economics, commonly accepted is "what goes up must come down one day, and the reverse is also true" so why including the [u]linear [/u]time trend in your model which blatantly violates this law when n --> infinity ? Some known efforts of mathematicians, statisticians, econometricians, economists have been published in journals to respond to those questions (eg. the work of John Blatt (mathematical meaning of a time trend), C Granger and many other econometricians (on unit root testing, co-integration and related issues), Ho-Trieu & Tucker (on logarithmic time trend which is [u]non-linear[/u] with results alluding to a proof rejecting the existence of linear trend, and linear trend is just a misnomer of a special form of cyclical trend when periodicity is large; please see http://ideas.repec.org/a/ags/remaae/12288.html for further details). To conclude, I support the use of just "regression".
Meaning of "regression coefficient"
editThe section "Introduction to linear regression" contains the passage " is a p-dimensional parameter vector. Its elements are also called effects, or regression coefficients." But doesn't the term "regression coefficient" conventionally refer to the estimated values of the betas, rather than the betas themselves? Duoduoduo (talk) 16:25, 24 November 2010 (UTC)

Random variables
editIn my opinion the article does not clearly distinguish between real variables and stochastic variables. Nijdam (talk) 23:01, 6 February 2011 (UTC)
Missing terms: point of averages, regression line, average of
editPoint of averages: The point whose x value is the average of all x values, and whose y is the value of all y values. http://www.youtube.com/watch?v=T7tj2-2r2Gk, at 4:30-5:00.
Graph of averages: If the x values are discrete, for each distinct x value, take the average of the corresponding y values. The set of points constitute the graph of averages. I believe this is defined for continuous data too, if the x axis is divided into intervals. Note that the there is a difference between the graph of averages of y values and the graph of values of x values. Source: http://www.youtube.com/watch?v=T7tj2-2r2Gk, at 5:00-5:30.
Regression line: "a smoothed version of the graph of averages". The regression line always passes through the point of averages. Source: http://www.youtube.com/watch?v=T7tj2-2r2Gk, at 6:00 - 7:00.
Could be nice, if these were defined in the article.
big
editI see no difference between

and

Why the "\big"? — Preceding unsigned comment added by Nijdam (talk • contribs) 29 September 2011
- If anyone still cares: both pairs of parentheses to the right of the second equals sign in the top equation are slightly bigger to accomodate the "1/n" fraction, which is slightly taller than the rest of the stuff in the parentheses. It is common in TeX to increase the size of the parentheses slightly when you put "tall" things (like fractions, larger-than-usual exponents, or sums showing the range of the index variable) inside parentheses. It is a matter of taste whether it's actually necessary in any particular case. - dcljr (talk) 10:00, 24 October 2015 (UTC)
a misnomer
edit"Linear Regression" is a misonomer. Francis Galton first spoke of reversion, then regression in reference to generational changes in heights of men (from father to son). Shorter sons having regressed so to speak.
"..in 1877, Galton first referred to "reversion" in a lecture on the relationship between physical characteristics of parent and offspring seeds. The "law of reversion" was the first formal specification of what Galton later renamed "regression." Thirteen Ways to Look at the Correlation Coefficient
Galton's law of reversion is about genetics and has nothing to do with the mathematics of least squares, although least squares IS the applied mathematics. But if you say "linear regression" over the phone from the consultant's office, it sounds more impressive, which might explain why it sticks. — Preceding unsigned comment added by 97.81.29.81 (talk) 19:58, 21 August 2012 (UTC)
Median-median line?
editThere doesn't seem to be a section here (or any article) about the median-median line, even though that's a popular regression technique. Is there a reason for that? -- Spireguy (talk) 19:23, 2 October 2012 (UTC)
Satistics or linear algebra
editI would have written the first sentence to classify it as linear algebra, rather than statistics. Is one more standard thn the other? I learned this in my linear algebra class. Mythirdself (talk) 19:15, 30 March 2013 (UTC)
Least distance fit
editAnyone an opinion on this?:
In the section "Least-squares estimation and related techniques" I guess it would be appropriate to add least distance fitting. Actually the result is rather simple:
Slope: beta = stdev(y) / stdev(x), possibly with a minus sign
Offset: epsilon = mean(y) - beta * mean(x)
Least distance fitting is practically useful when fitting data which is noisy in both x and y, for example correlation plots.
Thanks, Frank Fstaals (talk) 15:19, 13 August 2013 (UTC)
- Is this not just total least squares? - dcljr (talk) 10:05, 24 October 2015 (UTC)
Response variables
edit"Constant variance (aka homoscedasticity). This means that different response variables have the same variance in their errors, regardless of the values of the predictor variables." This was a confusing passage for me and I spent half an hour searching different sources to try and clear this up. Is it "different response variables" or "different values of the response variable"? The definition states there's only one response variable. Other sources also confirm that homoscedasticity refers to the variance in errors for the same variable. It's very confusing if you try to figure out what the sentence means if you were to have different response variables and you were comparing the variance in their errors. — Preceding unsigned comment added by 95.91.235.221 (talk) 09:10, 21 January 2014 (UTC)
- I think yi is one response variable for response i, but there are n of such response variables (i = 1..n), according to the definition. Every response variable has one (measured) value. Homoscedasticity means that these measurement errors have the same variance for all i. —PapaNappa (talk) 15:06, 7 December 2015 (UTC)

Errors and Residuals, confusing
editI think the term "error" is a little confusing and mixed in this article.
Sometimes it means the error (standard deviation) of all experimental y for a given x.
Sometimes it means the residuals, the distance from E[y|x] to the line, distance from the mean value of y for a given x to the line.
And the standard deviation sometimes refers to the first error, sometimes to the second.
- Feel free to improve the present article based on the errors and residuals article. Fgnievinski (talk) 19:23, 25 June 2015 (UTC)
Missing constant term
editDear main authors (are there any?);
thanks for writing this article. Here are 3 suggestions.
- In "Introduction to linear regression" it says: "... a linear regression model assumes that the relationship between the dependent variable yi and the p-vector of regressors xi is linear. This relationship is modeled through a disturbance term or error variable εi." → I believe the second sentence needs improvement. May be merge the two sentences?
- A linear relationship is , but the constant term is missing in the formulas.
- Notation:


- I believe the middle notation is not good practice. Instead of , better write (and add the constant term).



Regards, Herbmuell (talk) 06:27, 26 July 2015 (UTC)
- Often, to allow matrix notation to be used, [math]X_1[/math] is a constant term of 1's, thus the parameter [math]b_1{/math] is the intercept. -- PeterLFlomPhD (talk) 20:42, 20 August 2015 (UTC)
Is the MLE section misnamed or does it need to be split? Comment
editI am not sure that methods such as ridge and LASSO really fit perfectly in the MLE section -- PeterLFlomPhD (talk) 20:40, 20 August 2015 (UTC)
Regression of Y on X and X on Y compared to density contour
edit
I've just uploaded an image I cobbled together quickly illustrating how the ordinary least squares regression of Y on X connects the left- and rightmost points on a contour of the corresponding bivariate normal density (same means, variances, and covariance as the data), and that of X on Y connects the highest and lowest points on the same ellipse. (And, BTW, total least squares would give the major axis of the ellipse.) Unfortunately, I'm not quite sure how to make an accurate density contour with what I have to work with (Gnumeric), so I "faked" that part (adjusted "by eye"). I didn't find a similar image at Commons. Does anyone know of an appropriately licensed (completely accurate) image like this, or can anyone create one (say, with R)? I think such an image would be a nice addition to this article or one of the others I've linked to (i.e., those for OLS or TLS). - dcljr (talk) 10:29, 24 October 2015 (UTC)
- Well, I just ran across File:Galton's correlation diagram 1875.jpg, which is basically "the original" diagram of this type. I guess that should be used, since no one has taken it upon themselves to create a new one. - dcljr (talk) 07:12, 23 April 2017 (UTC)
Normally-distributed response variable?
editIn the "Constant variance" paragraph of Assumptions, it says "(e.g. fit the logarithm of the response variable using a linear regression model, which implies that the response variable has a log-normal distribution rather than a normal distribution)". I think the response variable has no such assumption of being normal-distributed, has it? (This wouldn't make any sense in a linear regression setting). Only the error is assumed to be normally distributed. However, I'm not going to edit this right now, because I'm not quite sure yet that the log-transformation also implies that the errors are log-normal distributed. —PapaNappa (talk) 15:16, 7 December 2015 (UTC)
- If Y is linearly related to X and the errors are normally distributed (usual assumptions), then Y is normally distributed; so this passage is referring to an implication of the usual assumptions. As for the log-normal issue, if the log of a variable is normal, then the original variable is log-normal — and, specifically in this case, if the log Y-vs.-X regression is linear with homoskedastic, normally-distributed, additive errors, then Y-vs.-X is nonlinear with heteroskedastic, log-normal, multiplicative errors. (I think I got all that right.) - dcljr (talk) 05:09, 8 December 2015 (UTC)
- You are right, that's clear now. Should this implication be stated somewhere before these paragraphs? Or we should just replace "response variable" with "error term" or similar to avoid this confusion. —PapaNappa (talk) 13:34, 9 December 2015 (UTC)
- Not sure the best fix. That item ("Constant variance") is rather wordy, and could stand to be streamlined a bit. I may take a crack at it at some point, but in the meantime, feel free to submit whatever changes you feel would improve it. - dcljr (talk) 20:01, 9 December 2015 (UTC)
- You are right, that's clear now. Should this implication be stated somewhere before these paragraphs? Or we should just replace "response variable" with "error term" or similar to avoid this confusion. —PapaNappa (talk) 13:34, 9 December 2015 (UTC)
Linear with respect to regressors or coefficients?
editGiven a data set of n statistical units, a linear regression model assumes that the relationship between the dependent variable yi and the p-vector of regressors xi is linear.

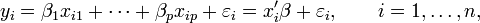{kind=link}
{kind=link}
{kind=link}
Quick sanity check: should this not instead read that the model is linear with respect to its parameters/coefficients? I assume the above was written to refer to a model expressed in standard form, but I don't think that's clear here, especially to an uninformed reader. The article itself quickly counters the above verbiage in the physics example that follows and in the discussion of the linearity assumption. It's great that there's a link to linearity, but it seems like anyone who took the time to read that article and came back to this article would be promptly confused. Ingcake (talk) 01:14, 29 December 2015 (UTC)
- The model is linear in the sense discussed at Linear function#As a polynomial function, as explicitly illustrated in this article immediately after the statement you allude to (i.e., displayed as a linear combination). The "physics example" does not contradict the linearity assumption, as it is clearly set up with x1 = t and x2 = t². (In particular, the model does not have to be linear in the variable t, since t and t² are two different regressors, and the model is linear in these two regressors, as discussed in the "Assumptions" section.) So, the answer to the question in your section heading is: the model is "linear with respect to both the regressors and the parameters". I'm not sure making a distinction between "linear in the parameters" vs. "linear in the regressors" is really necessary. In the model itself there is no such distinction. And if you look at the Nonlinear regression article, the example they give there is also nonlinear in both the parameters and regressors. Is there an example of a "nonlinear regression" model that is nonlinear in the parameters but linear in the regressors (not counting examples that can easily be transformed to be linear in both)? - dcljr (talk) 07:54, 29 December 2015 (UTC)
- I agree with user Ingcake, the meaning of 'linear' is confusing in the entry and should be made clearer, even in the lead section --Forich (talk) 13:58, 12 June 2017 (UTC)
Citations
editAside from the first part of the article, citations are not provided or are missing for the most part. Some work should be put into adding reliable resources for the information provided. Also, additional discussion on the applications of linear regression would be helpful to round out the article. Lond6846 (talk) 17:07, 26 January 2017 (UTC)
External links modified
editHello fellow Wikipedians,
I have just modified one external link on Linear regression. Please take a moment to review my edit. If you have any questions, or need the bot to ignore the links, or the page altogether, please visit this simple FaQ for additional information. I made the following changes:
- Added archive https://web.archive.org/web/20110611114740/http://www.ec.gc.ca/esee-eem/default.asp?lang=En&n=453D78FC-1 to http://www.ec.gc.ca/esee-eem/default.asp?lang=En&n=453D78FC-1
When you have finished reviewing my changes, you may follow the instructions on the template below to fix any issues with the URLs.
This message was posted before February 2018. After February 2018, "External links modified" talk page sections are no longer generated or monitored by InternetArchiveBot. No special action is required regarding these talk page notices, other than regular verification using the archive tool instructions below. Editors have permission to delete these "External links modified" talk page sections if they want to de-clutter talk pages, but see the RfC before doing mass systematic removals. This message is updated dynamically through the template {{source check}} (last update: 5 June 2024).
- If you have discovered URLs which were erroneously considered dead by the bot, you can report them with this tool.
- If you found an error with any archives or the URLs themselves, you can fix them with this tool.
Cheers.—InternetArchiveBot (Report bug) 10:11, 16 May 2017 (UTC)
Confusion between "general linear models" and "multivariate linear models"
editThe subsection on "general linear models" really is about "multivariate linear models" as described in that section, namely, regression with multiple outcomes. The "general linear model" is something different as described in the Wikipedia article on the General linear model, namely, regression with both continuous and categorical predictors. I propose to rename this subsection to "multivariate linear models" and to add a new subsection on "general linear models". --Hapli (talk) 11:09, 1 August 2017 (UTC)
- Actually the article you linked, General linear model, correctly says that it refers to multivariate models. It says nothing about models with both continuous and categorical predictors. Our subsection "General linear model" is correctly about multivariate models. Two subsections later we have a subsection "Generalized linear model", which is correctly about bounded or discrete dependent variables, as is the article Generalized linear model. Loraof (talk) 21:17, 23 August 2017 (UTC)
Inconsistencies in defining the constant term and its relation to p.
editThe definition of the constant term is at some places done by explicitly including a set of n 1-s, index 0 and independent variables indexed from 1 to p. At other places the independent variables' index range is still 1 to p but index 1 is appointed for the constant term, and there's no index 0. In the first case there are really p independent variables and the constant term, in the second case only p-1 actual independent variables plus 1 constant term. Example for the first case:
β, is a (p + 1)-dimensional parameter vector, where β0 is the constant (offset) term.
Example for the second case:
Usually a constant is included as one of the regressors. For example, we can take xi1 = 1 for i = 1, ..., n. The corresponding element of β is called the intercept.
2A00:23C5:7506:9C00:A02A:639:32C7:138F (talk) 16:08, 26 March 2018 (UTC)
- Thanks. I’ve fixed it. Loraof (talk) 21:05, 5 May 2018 (UTC)
Simplify?
editThis article is *way* to complicated for such a simple subject. Can some of the concepts be moved to independent pages and linked to? I think somewhere between that of "Simple English" https://simple.wikipedia.org/wiki/Linear_regression and the current version would be the optimal solution. Anyway, those are just my thoughts. 81.104.142.198 (talk) 18:17, 12 May 2018 (UTC)
- I think maybe you're seeing the article as "complicated" because it is a very general subject (not a "simple" one) that has many special cases. The article mentions those special cases and links to articles about them (e.g., simple linear regression), which may (or may not!) be seen as "simpler" than this one. I'm not sure "simplifying" this article is really possible — although I am certainly not saying it couldn't do with a thorough copyedit. Do you have specific suggestions about what material you think should be moved into separate articles? - dcljr (talk) 20:56, 12 May 2018 (UTC)
Mathematical Notation
editRight from the start of the "introduction", this article launches into specialized notation that only pre-trained readers will understand. For the rest of us who are encountering these symbols here for the first time, there needs to be a math-lib link to "how to read the curly brackets etc". Mathematics PhDs may scoff, but prefacing the arcana with a how-to-read link will increase readership. — Preceding unsigned comment added by Jeffryfisher (talk • contribs) 23:17, 17 December 2018 (UTC)
Errors in illustration of "independence of errors"
editIn the section on Assumptions, it says: "Independence of errors. This assumes that the errors of the response variables are uncorrelated with each other (see plot)". The plot is a plot of residuals against the predicted values. In the caption of that plot it says: "Residuals that appear to be evenly distributed below and above 0, such as the plot above, indicate that the errors of the regression model are independent of predicted values, thus meeting the assumption." In my opinion that is incorrect. That the residuals are independent of the predicted values does not imply that they meet the assumption of independence. Even if they are independent of the predicted values they could still be autocorrelated or they could depend on some unmodelled variable, neither of which would be visible in this plot.
The caption goes on to say: "Plots with unevenly distributed residuals would indicate a violation of the assumption". That too is misleading. If the residuals are independent but not identically distributed, for example due to heteroscedasticity, then this would lead to unevenly distributed residuals, but would not indicate a violation of the independence assumption.
I propose that we simply delete that plot, because it gives the misleading impression that in real-world data one would expect such a regular distribution of residuals. Delius (talk) 23:01, 8 May 2021 (UTC)
- I've tried to improve the caption. FWIW. - dcljr (talk) 22:20, 11 May 2021 (UTC)