

Uvod
editU računarstvu, trie, ponekad nazivano i radix stablo ili prefiksno stablo (jer se pretraga može vršiti po prefiksu), je struktura podataka u obliku uređenog stabla koja se koristi za čuvanje dinamičkih skupova ili acocijativnih nizova kod kojih su ključevi predstavljeni stringovima. Za razliku od binarnog stabla pretrage, nijedan čvor u stablu ne sadrži ključ povezan sa tim čvorom već pozicija čvora u stablu definiše njegov ključ. Svi potomci jednog čvora imaju zajednički prefiks stringa koji je povezan sa tim čvorom, a koren je povezan sa praznim stringom. Vrednosti se uglavnom ne povezuju sa svakim čvorom već samo sa listovima i nekim unutrašnjim čvorovima koji odgovaraju ključevima preseka. Za prostorno-optimizovanu verziju prefiksnog stabla, videti kompaktno prefiksno stablo.
Termin trie je prvi koristio Edward Fredkin, koji je izgovarao /ˈtriː/ "tree", kao u retrieval. Drugi autori izgovaraju /ˈtraɪ/ "try", kako bi se razlikovalo od "tree". U prikazanom primeru, ključevi su u čvorovima a vrednosti ispod njih. Svaka cela reč ima proizvoljnu celobrojnu vrednost povezanu sa njom. Trie može da se vidi kao determinističko konačni automat, iako je simbol grane često implicitan u poretku grana. Nije neophodno da se ključevi eksplicitno čuvaju u čvorovima. (Na slici, reči su prikazane samo zbog ilustracije rada strukture.) Trie strukture podataka se najčešće koriste za niske karaktera ali imaju i drugu primenu. Isti algoritmi se mogu prilagoditi da služe kod uređenih lista različitih tipova, npr. kod permutacija liste cifara ili oblika.
Primena
editKao zamena za druge strukture podataka
editTrie ima brojne prednosti u odnosu na binarno stablo pretrage. Trie se može koristiti kao zamena heš tabela, u odnosu na koje ima sledeće prednosti:
- Pretraga trie-a je brža u najgorem slučaju, vreme O(m) (gde je m dužina traženog stringa), u odnosu na lošiju heš tabelu. Lošija heš tabela može imati kolizije ključeva (heš funkcija slika različite ključeve na istu poziciju heš tabele). U najgorem slučaju, pretraga u lošijoj heš tableli je vremenske složenosti O(N), ali mnogo češće O(1) sa vremenskom složenošću O(m) evaluacije heš tabele.
- Ne postoji kolizija različitih ključeva u trie-u.
- Prostor za skladištenje podataka sa istim ključem je potreban samo ako se podaci razlikuju.
- Nema potrebe za heš funkcijom ili za zamenom heš funkcije novom kada se doda više ključeva trie-u.
- Trie može pružiti alfabetsko uređenje vrednosti po ključu.
Kod trie struktura podataka postoje i loše strane:
- Trie može biti sporije od heš tabele pri pretrazi, posebno kada su podaci čuvani na diskovima sa direktnim pristupom ili drugim uređajima sekundarne memorije kod kojih je random-access vreme pristupa veliko u poređenju sa glavnom memorijom.
- Neki ključevi, kao što su brojevi sa pokretnim zarezom, mogu dovesti do velikih lanaca prefiksa koji su beskorisni. Ipak, bitovski trie može da radi sa standardom IEEE.
- Neki trie može koristiti više memorije nego heš tabela, jer se memorija alocira za svaki karakter u traženom stringu za razliku od jednog parčeta memorije koje se alocira kod heš tabele za traženi string.
Kao predstavljanje rečnika
editČesta primena trie-a je kod čuvanja prediktivnog teksta ili autokompletiranja rečnika, što se može naći na mobilnom telefonu. Takva primena koristi mogućnost trie-a da brzo vrši pretragu, ubacivanje i brisanje vrednosti; ipak, ako je čuvanje reči iz rečnika sve što je potrebno (tj. ako nije potrebno čuvanje dodatnih informacija uz reči), minimalni deterministički aciklični konačni automat koristi manje memorije nego trie. Trie se koristi i kod implementacije algoritama približnog poređenja, kao i kod provere pravopisa.
Algoritmi
editPretraga u trie-u se može opisati lako. Neka je tip trie-a rekurzivan, u svakom čvoru se sadrži lista trie potomaka, indeksirani sledećim karakterom, a svaki čvor opciono sadrži i vrednost. Ovde je ovaj tip podataka predstavljen u Haskell-u:
import Prelude hiding (lookup)
import Data.Map (Map, lookup)
data Trie a = Trie { value :: Maybe a,
children :: Map Char (Trie a) }
Vrednost se u trie-u može pretražiti na sledeći način:
find :: String -> Trie a -> Maybe a
find [] t = value t
find (k:ks) t = do
ct <- lookup k (children t)
find ks ct
U imperativnom stilu, pod pretpostavkom da već postoji odgovarajući tip podataka, može se opisati isti algoritam u Python-u. children predstavlja mapu potomaka čvora.; and we say that a "terminal" node is one which contains a valid word.
def find(node, key):
for char in key:
if char not in node.children:
return None
else:
node = node.children[char]
return node.value
Ubacivalje novog elementa se odvija prolaskom kroz trie po stringu koji se ubacuje a zatim dodavanjem novih čvorova za sufiks stringa koji se ne sadrži u trie-u. U imperativnom pseudokodu:
algorithm insert(root : node, s : string, value : any):
node = root
i = 0
n = length(s)
while i < n:
if node.child(s[i]) != nil:
node = node.child(s[i])
i = i + 1
else:
break
(* dodavanje novih čvorova ako je potrebno *)
while i < n:
node.child(s[i]) = new node
node = node.child(s[i])
i = i + 1
node.value = value
Sortiranje
editLeksikografsko sortiranje skupa ključeva se može postići sledećim algoritmom baziranom na trie strukturi:
- Ubaciti sve ključeve u trie.
- Odštampati sve ključeve trie-a putem prefiksnog obilaska stabla, što čini da izlaz bude u leksikografskom poretku.
Ovaj algoritam je varijacija radiks sort-a.
Trie je osnovna struktura podataka Burstsort-a, koji je (2007.) bio najbrži poznati algoritam za sortiranje stringova. Kasnije su otkriveni i brži algoritmi za sortiranje stringova.
Pretraživanje punog teksta
editPosebna vrsta trie-a, sufiksno stablo, može se koristiti u indeksiranju svih sufiksa u tekstu kako bi se primenilo brzo pretraživanje punog teksta.
Bitski trie
editBitski trie je sličan normalnom trie-u koji je zasnovan na karakterima, osim što se u ovom slučaju obilazak vrši pomoću induvidualnih bitova, čineći strukturu binarnim stablom. Implementacije ove strukture koriste posebne CPU instrukcije da se brzo pronađe bit prvog skupa iz ključa određene dužine(npr. kod GCC-a to je instrukcija __builtin_clz()). Ova vrednost se potom koristi u indeksiranju tabele veličine 32 ili 64 koja pokazuje na prve elemente bitskog trie-a sa tim brojem vodećih nula. Pretraga se potom sastoji iz provere svakog sledećeg bita iz ključa odabirom child[0] ili child[1] potomka dok se ne nađe traženi element.
Zbog dobrih mogućnosti keširanja i paralelizovanja, ovaj proces je veoma brz na modernim procesorima. Na primer, crveno-crno stablo ima bolje performanse u teoriji ali u praksi ne pokazuje dobre rezultate jer algoritam zavisi više od memorijske latence nego od brzine procesora. Kako bitski trie pristupa memoriji samo zbog čitanja, ova struktura podataka postaje popularna kod kodova koji sadrže puno ubacivanja i brisanja, kao što su memorijski alokatori (npr. novije verzije poznatog alokatora Doug Lea-a (dlmalloc) i njegovih potomaka).
Primer implementacije bitskog trie-a u C-u i C++-u može se naći na sledećoj adresi: http://www.nedprod.com/programs/portable/nedtries/.
Kompresujući trie
editKada je trie uglavnom statično, tj. kada operacije ubacivanja i brisanja elemenata ne postoje a izbršava se samo pretraga, kada čvorovi nisu vezani ključevima koji su zavisni od podataka u tom čvoru, moguće je kompresovati reprezentaciju trie-a spajanjem istih grana.[1] Ovakava trie se uglavnom koristi pri kompresovanju tabela pretraživanja gde je skup ključeva vrlo redak u odnosu na prostor podataka. Može se koristiti u predstavljanju retke bitset-ove (npr. podskupove mnogo većih fiksnih naprojivih skupova) koristeći trie čiji su ključevi sastavljeni od stringa bitova koji predstavlja celobrojnu poziciju elementa u skupu. Trie će tada imati degenerisan oblik sa nedostajućim granama, a kompresija se omogućava čuvanjem listova stabla (delovi skupa sa fiksiranom dužinom) i njihovim kombinovanjem kada se ustanovi da sadrže iste delove ili popunjavanjem odgovarajućih praznina.
Ovakva kompresija se koristi i u implementacijama raznih tabela za brzu pretragu koje vraćaju karakteristike Unikod karaktera (npr. tabele pretrage koje sadrže kombinacije baznih i kombinovanih karaktera koji su potrebni u normalizaciji Unikod-a). Za takve primene, reprezentacija je slična transformisanju velikih jednodimenzionih retkih tabela u višedimenzione matrice a potom korišćenje kooridinata hiper-matrice kao string ključ nekompresovanog trie-a. Kompresija se tada sastoji u pronalaženju i spajanju istih kolona hiper-matrice kako bi se kompresovala poslednja dimenzija u ključu; svaka dimenzija hiper-matrice sadrži početnu poziciju u vektoru sledeće dimenzije za vrednost svake koordinate, a rezultujući vektor se može kompresovati ako je takođe redak, tako da se svaka dimenzija (vezana za jedan nivo u trie-u) može kompresovati posebno.
Neke implementacije podržavaju takve kompresije u dinamičkom retkom trie-u sa omogućenim unošenjem i brisanjem elementa trie-a. Ovakve implementacije imaju značajan trošak pri razdvajanju i spajanju grana, a određeni kompromise se prave između najmanje veličine kompresovanog trie-a i brzine ažuriranja, ograničavajući globalnu pretragu za upoređivanje istih grana u retkom trie-u.
Jedan od drugih načina kompresije je preslikavanje strukture podataka u niz bajtova.[2] Ovaj pristup ne zahteva pokazivače na čvorove, što značajno smanjuje memorijske potrebe i omogućava memorijsko mapiranje i efikasno punjenje virtualne memorije.
Prednosti u odnosu na druge algoritme pretrage
edit- A series of graphs showing how different algorithms scale with number of items
-
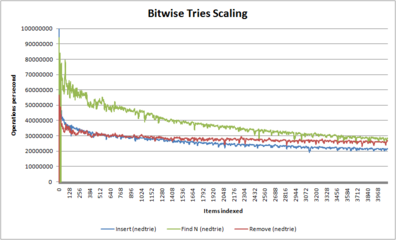 Ponašanje Fredkin trie-a u funkciji veličine
Ponašanje Fredkin trie-a u funkciji veličine
(u ovom slučaju, nedtrie-ovi, što je implementacija u mestu, i zato ima strmiju krivu u odnosu na dinamičke implementacije trie-ova) -
 Ponašanje crveno-crnog stabla u funkciji veličine
Ponašanje crveno-crnog stabla u funkciji veličine
(u ovom slučaju, BSD-ov rbtree.h, pokazuje klasičnu O(log N) složenost) -
 Ponašanje heš tabela u funkciji veličine
Ponašanje heš tabela u funkciji veličine
(u ovom slučaju, uthash, koji u proseku pokazuje O(1) složenost)



Za razliku od drugih struktura podataka, trie ima jedinstvenu osobinu da je vreme ubacivanja, brisanja i pretraživanja praktično isto. Stoga, u problemima u kojima je u istoj meri zastupljeno ubacivanje, brisanje i pretraživanja elemenata, trie pruža bolje performanse od binarnog stabla pretrage a pruža i bolju osnovu za CPU instrukcije i keširanje grana.
Glavne prednosti trie-a nad binarnim stablom pretrage (BSP) su:
- Pretraga ključeva je brža. Pretraga ključa dužine m ima vremensku složenost O(m). BSP vrši O(log(n)) poređenja ključeva, gde je n broj elemenata stabla, jer pretraga zavisi od visine stabla koje je logaritamsko ako je stablo balansirano. Stoga, u najgorem slučaju, pretraga u BSP-u ima O(m log n) vremensku složenost. Takođe, operacije koje koristi trie pri pretrazi (pristup nizu preko indeksa koji je karakter) su brze na realnim mašinama.
- Trie je prostorno efikasnija struktura kada sadrži veliki broj kratkih ključeva, jer su čvorovi zajednički ključevima sa istim prefiksima.
- Trie olakšava problem Najdužeg zajedničkog prefiksa.
- Broj unutrašnjih čvorova od korena do listova je jednak dužina ključa, tako da nema potrebe za balansiranjem stabla.
Glavne prednosti trie-a nad heš tabelom su:
- Trie podržava uređene iteracije dok su iteracije nad heš tabelom u pseudorandom poretku, što zavisi od heš funkcije kao i rešavanja kolizija (koje je određeno implementacijom)
- Trie olakšava problem Najdužeg zajedničkog prefiksa.
- Trie je u proseku brži pri ubacivanju elementa od heš tabele jer heš tabela mora da prepravi indekse kada postane puna, što je skupa operacija. Trie stoga ima bolje ograničenu vremensku složenost u najgorem slučaju.
- Za ključeve manje dužome, trie je brži jer nema korišćenja heš funkcije.
Vidi još
edit- Суфиксно стабло
- Радикс стабло
- Directed acyclic word graph (aka DAWG)
- Ternary search tries
- Acyclic deterministic finite automata
- Hash trie
- Deterministic finite automata
- Judy array
- Search algorithm
- Extendible hashing
- Hash array mapped trie
- Prefix Hash Tree
- Burstsort
- Luleå algorithm
- Huffman coding
- Ctrie
- HAT-trie
Notes
edit- ^ Jan Daciuk, Stoyan Mihov, Bruce W. Watson, Richard E. Watson (2000). "Incremental Construction of Minimal Acyclic Finite-State Automata". Computational Linguistics. 26. Association for Computational Linguistics: 3. doi:10.1162/089120100561601. Archived from the original on 2006-03-13. Retrieved 2009-05-28.
This paper presents a method for direct building of minimal acyclic finite states automaton which recognizes a given finite list of words in lexicographical order. Our approach is to construct a minimal automaton in a single phase by adding new strings one by one and minimizing the resulting automaton on-the-fly
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ Ulrich Germann, Eric Joanis, Samuel Larkin (2009). "Tightly packed tries: how to fit large models into memory, and make them load fast, too" (PDF). ACL Workshops: Proceedings of the Workshop on Software Engineering, Testing, and Quality Assurance for Natural Language Processing. Association for Computational Linguistics. pp. 31–39.
We present Tightly Packed Tries (TPTs), a compact implementation of read-only, compressed trie structures with fast on-demand paging and short load times. We demonstrate the benefits of TPTs for storing n-gram back-off language models and phrase tables for statistical machine translation. Encoded as TPTs, these databases require less space than flat text file representations of the same data compressed with the gzip utility. At the same time, they can be mapped into memory quickly and be searched directly in time linear in the length of the key, without the need to decompress the entire file. The overhead for local decompression during search is marginal.
{{cite web}}: CS1 maint: multiple names: authors list (link)
Reference
edit- de la Briandais, R. (1959). "File Searching Using Variable Length Keys". Proceedings of the Western Joint Computer Conference: 295–298.